 |
Einführung in Betriebssystemevon Prof. Jürgen Plate |
|
Einführung in Betriebssystemevon Prof. Jürgen Plate |
Vom Beginn der "Rechnergeschichte" bis heute kann das Phänomen beobachtet werden, daß der Bedarf an Arbeitsspeicher immer größer ist als der verfügbare physische Speicher. Fast immer ist der verfügbare Speicher zu klein, um ein großes Programm oder mehrere Programme gleichzeitig aufzunehmen. Im Lauf der verschiedenen Rechnergenerationen wurden eine Reihe von Lösungen für dieses Problem entwickelt.
Die moderneren Methoden gehen dabei von der Tatsache aus, daß zu einem beliebigen Zeitpunkt nur auf wenige Speicherplätze tatsächlich zugegriffen wird, während die anderen nur für einen späteren Zugriff (der u.U. nie erfolgt) bereitstehen. Die Grundidee ist also eine Erweiterung der Speicherkapazität unter Zuhilfenahme externer Massenspeicher, von denen bei Bedarf die benötigten Informationen in den Arbeitsspeicher geladen werden. In diesem Fall muß die Speicherverwaltung in der jeweiligen Situation festlegen, welche Programmabschnitte geladen werden sollen und welche auf dem Hintergrundspeicher bleiben sollen. Insbesondere beim Multiprogramming und beim Multitasking-Betrieb entstehen für die Speicherverwaltung vielfältige Aufgaben, denn es müssen sich mehrere unabhängige Programme im Hauptspeicher befinden, die u.U. häufig aus- und eingelagert werden müssen. Zu den Aufgaben der Speicherverwaltung gehört es auch, Mechanismen für den Schutz vor unbefugten Speicherzugriffen aus anderen Programmen bereitzustellen. Die folgende Auflistung von Speicherverwaltungsprinzipien beginnt mit den einfachsten - meist älteren und endet bei den heute üblichen Methoden des Memory-Management" in Universalrechnern.
Es gilt:
Prozesse dürfen nur auf Bereiche innerhalb der Partition zugreifen (gilt für Code und Daten!), da sonst andere Prozesse unzulässig beeinflußt werden könnten. Die Speicherverwaltungseinheit muß also entsprechende Schutzfunktionen besitzen und Zugriffe auf "verbotene" Bereiche an den Betriebssystem-Kern melden. Eine Lösung besteht beispielsweise in zwei zusätzlichen Registern des Prozessors, Base- und Limit-Register. Das Baseregister enthält die Startadresse der dem aktiven Prozeß zugeordnenten Partition und das Limitregister deren Länge. Alle Adressierungsvorgänge im Programm erfolgen relativ zum Base-Register. Eine Änderung der beiden Register erfolgt durch den Scheduler.
Die flexiblere Lösung besteht darin, die Bibliotheksroutinen so aufzubereiten, daß die Festlegung der von ihnen benötigten Speicherplätze bis zum Ladezeitpunkt aufgeschoben werden kann. Man benötigt dazu einen "verschiebenden Lader" (Relocating Loader), der dann auch gleich zum Laden der Benutzerprogramme verwendet werden kann.
Die Aufbereitung der Programme besteht darin, die Adreßteile der Maschinenberfehle als absolute bzw. relative Adressen zu kennzeichnen. Somit besteht die Aufgabe des verschiebenden Laders darin, zu den relativen Adressangaben nur noch einen konstanten Offset zu addieren (die Lade-Startadresse des Programms) und diese nun absolute Adressangabe abzuspeichern; Voraussetzung ist natürlich, daß die Programme so geschrieben sind, als würden sie ab Adresse Null im Speicher zu liegen kommen. Es wird also zum Ladezeitpunkt jede relative Adresse in eine absolute umgeformt, wodurch der Ladvorgang mehr Zeit in Anspruch nimmt. Das geladene Programm kann nicht mehr verschoben werden, wenn es sich im Hauptspeicher befindet.
Eine weitere Steigerung der Flexibilität ist dann gegeben, wenn die Umsetzung in effektive Adressen nicht zum Ladezeitpunkt, sondern erst unmittelbar bei Ausführung des Befehls vorgenommen wird. Voraussetzung dafür ist ein Prozessor, der entsprechende Adressierungsarten der Befehle erlaubt. Dazu muß ein Adreßrechenwerk im Prozessor vorhanden sein, das entweder den Inhalt eines Basisadressregisters (geladen durch das Ladeprogramm; "basisregister-relative Adressierung") oder den Inhalt des Program-Counters addiert ("position independent code", "relocatible code" durch "PC-relative Adressierung"). Die Adressangaben bei den Befehlen werden also nicht mehr vom Lader modifiziert, der Ladevorgang läuft wesentlich schneller ab. Das Programm kann nach dem Laden noch verschoben werden.
Die Zerlegung eines Programms in Teile (Segmente), welche nicht gleichzeitig im Arbeitsspeicher sein müssen, muß der Programmierer vornehmen, weil es für den Compiler und den Linker keine praktikable Möglichkeit gibt, dies automatisch zu tun. Nur der Programmierer kann vorhersagen, in welcher Kombination verschiedene Programmteile zusammenarbeiten werden und sich daraufhin eine entsprechende Overlay-Struktur überlegen. Eine ungünstige Struktur wird zu unnötig vielen verlangsamenden Ladevorgängen führen.
Eine Overlay-Struktur besteht aus

Eine ähnliche Technik, die ohne gemeinsames Hauptprogramm auskommt, bezeichnet man als "Chaining" (Verketten). Eigenständige Programmodule rufen sich gegenseitig auf und werden von diesen vollständig überlagert (typisch für BASIC).
Wenn aufgrund eines sehr ungünstigen Verhältnisses zwischen Programmgröße und Arbeitsspeichergröße ein mehrfach geschachteltes �berlagern nötig wird - innerhalb eines Überlagerungssegmentes wird wieder überlagert usw. - dann kann der Arbeitsaufwand für die Erstellung einer effizienten Overlay-Struktur erheblich werden!
Dabei werden mehrere Speicherbänke von jeweils bis zu 64 KByte im Rechner implementiert. Zu jedem Zeitpunkt ist nur eine Speicherbank freigegeben und somit für Programm und Daten zugänglich. Die Umschaltung auf eine andere Speicherbank erfolgt über einen Speicherbank-Selektor (realisiert als Parallel-AusgabeBaustein), der z. B. mit Hilfe eines Ausgabe-Befehls angesprochen werden kann. Zu Kommunikationszwecken kann ein Speicherbereich allen Speicherbänken gemeinsam zugeordnet werden (Common).

In Multitasking-Systemen können so z. B. die Task-Adreßräume unabhängig voneinander verwaltet werden, wenn jeder Task eine eigene Speicherbank zugewiesen wird. Dadurch wird aber zugleich die Zahl der möglichen Tasks durch die vorhandenen Speicherbänke begrenzt. Zusätzlicher Vorteil bei ungünstigen Umgebungsbedingungen: auf diese Weise wird ein rotierender magnetischer Massenspeicher vermieden!
Der Adreßraum, auf den sich die Programmbefehle beziehen, ist der logische Adreßraum. Der Adreßraum des realen Arbeitsspeichers ist der physische Adreßraum. --> Programme können unabhängig vom physischen Adreßraum geschrieben werden.
Der logische Adreßraum beschreibt einen gedachten, nicht real vorhandenen Arbeitsspeicher, den man als virtuellen Speicher bezeichnet.
Normalerweise ist der logische Adreßraum größer als der physische Adreßraum (meist sogar sehr viel größer). Der virtuelle Speicher wird auf der Platte abgebildet. Zur Ausführung muß ein Programm in den Arbeitsspeicher geladen werden. Wegen der sequentiellen Abarbeitung werden innerhalb eines bestimmten Zeitintervalls nicht alle Teile des Programms und analog auch nicht der gesamte Datenbereich des Programms benötigt.
Es reicht also aus, nur die jeweils benötigten Programm- und Datenbereichs-Teile (= "working set") im Arbeitsspeicher zu halten. Die Programme und Daten werden in einzelne Teilabschnitte zerlegt, die dann nur bei Bedarf (wenn sie von der CPU benötigt werden) in den Speicher geladen werden.

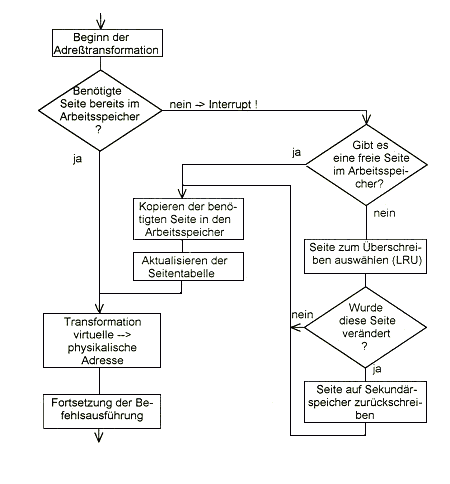
Die logische Adresse in den Befehlen bleibt auch nach dem Laden in den Arbeitsspeicher unverändert erhalten. Die Transformation erfolgt erst bei der Befehlsausführung --> dynamische Adreßtransformation (DAT). Liegt eine Adresse in einem Programm- oder Datenabschnitt, der sich nicht im Arbeitsspeicher befindet, wird der entsprechende Abschnitt nachgeladen.
Zur Realisierung der vituellen Speicherverwaltung muß eine Kombination aus Hard- und Software eingesetzt werden. Das Nachladen der Programm- und Datenabschnitte besorgt ein speziell konzipiertes Betriebssystem. Grundvoraussetzung für die Realisierung ist die Fähigkeit der CPU, einen laufenden Befehl zu unterbrechen (beim Nachladen) und nach erfolgtem Nachladen den begonnenen Befehl erneut aufzusetzen und dann vollständig auszuführen. Die virtuelle Speichertechnik ist für den Anwender vollkommen transparent. Sowohl das Nachladen von Programm- und Datenabschnitten als auch die Adreßumsetzung geschieht automatisch und braucht bei der Anwendungsprogrammierung nicht berücksichtigt zu werden. Die Aufteilung des Speichers kann erfolgen als:
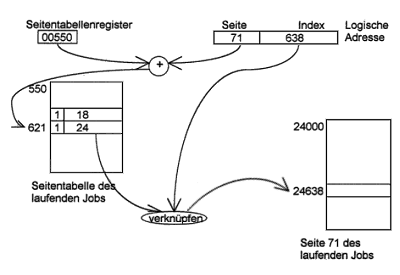
Die logische Adresse besteht aus 2 Teilen:
Für die in den Arbeitsspeicher geladenen Segmente ist in einer Segmenttabelle die jeweilige reale Anfangsadresse des Segments festgehalten (Basisadresse des Segments). Im Multiprogramming-Betrieb werden für die verschiedenen "Jobs" meist jeweils eigene Tabellen bereitgestellt damit mit den Segment-Nummern verschiedener Jobs keine Verwechslung möglich ist. Somit muß vor dem Segmenttabellenzugriff noch der Inhalt eines jobspezifischen Segmenttabellenregisters zur Segmentnummer addiert werden. Bei jedem Umschalten der Jobs (z. B. wegen "Verdrängen" einer Task am Zeitscheibenende) muß deshalb auch das Segmenttabellenregister umgeladen werden! Im allgemeinen enthält die Segmenttabelle auch Angaben über die Größe der Segmente (Angabe der letzten physischen Adresse des Segments oder der Segmentgröße direkt). Dadurch können fehlerhafte Zugriffe, die aus dem Segment herausführen, erkannt und verhindert werden.
Weiterhin sind in der Segmenttabelle jedem Segment noch Zustands- und Zugriffsinformationen zugeordnet (Erkennen nicht geladener Segmente, Verhinderung unberechtigter Zugriffe). Das Segment ist die kleinste Austauscheinheit. Falls kein Speicherplatz zum Nachladen mehr frei ist, muß ein vorhandenes, derzeit nicht benötigtes Segment entfernt werden ("demand segment swapping").
Probleme (gleichzeitig Nachteile der Segmentierung):
Wegen der festen Seitengröße liegt auch die Grenze zwischen Wortadresse und Seitennummer immer an der gleichen Stelle. Die physische Seitennummer muß mittels der Adreßtransformation aus der logischen Seitennummer ermittelt werden.
Die Adreßtransformation findet erst zum Zeitpunkt der Ausführung eines Befehls statt, man spricht deshalb von einer dynamischen Adreßumsetzung. Sie geschieht i. a. unter Verwendung einer Adreßumsetzungstabelle (Adreßumsetzungsspeicher, translation buffer), die für die im Arbeitsspeicher befindlichen Seiten die Zuordnungspaare (log. Seitennummer, phys. Seitennummer) enthält.
Besonders vorteilhaft für diesen Zweck sind sogenannte Assoziativspeicher (= CAM, Content Addressable Memory), deren Zugriff nicht über eine Adresse, sondern über Zelleninhalte erfolgt. Es wird ein Suchwort (Schlüssel) anstatt der Adresse angelegt und als Ergebnis erhält man eine Trefferanzeige, u. U. auch keinen Treffer. Der Schlüssel ist in diesem Fall die logische Seitennummer, 'Treffer' bedeutet, es existiert ein entsprechender Eintrag in der Tabelle, im speziellen Fall der Adreßumsetzung: die gesuchte logische Seite ist geladen, die eigentliche Information des Tabelleneintrags, die physische Seitennummer, wird ausgelesen.
Meldet der Assoziativspeicher keinen Treffer, (d. h. die Seite befindet sich nicht im Arbeitsspeicher --> "Page Fault") so wird das Laden dieser Seite eingeleitet (Seitenwechsel und Eintrag in die Tabelle!).

Vorteile des Paging-Verfahrens (gegenüber Segmentierung):
 Zum vorhergehenden Abschnitt Zum vorhergehenden Abschnitt |
 Zum Inhaltsverzeichnis Zum Inhaltsverzeichnis |
 Zum nächsten Abschnitt Zum nächsten Abschnitt |