2. Suchen und Sortieren
2.3 Mergesort
Jetzt lernen wir den ersten "effizienten" Algorithmus kennen: Mergesort. Dieser Algorithmus teilt array in zwei gleich große Hälften array1 und array2, sortiert diese (rekursiv, durch einen Aufruf von Mergesort selbst), und verschmilzt die beiden sortieren Teil-Arrays mit Hilfe einer Subroutine merge zu einer großen sortieren Gesamtliste.







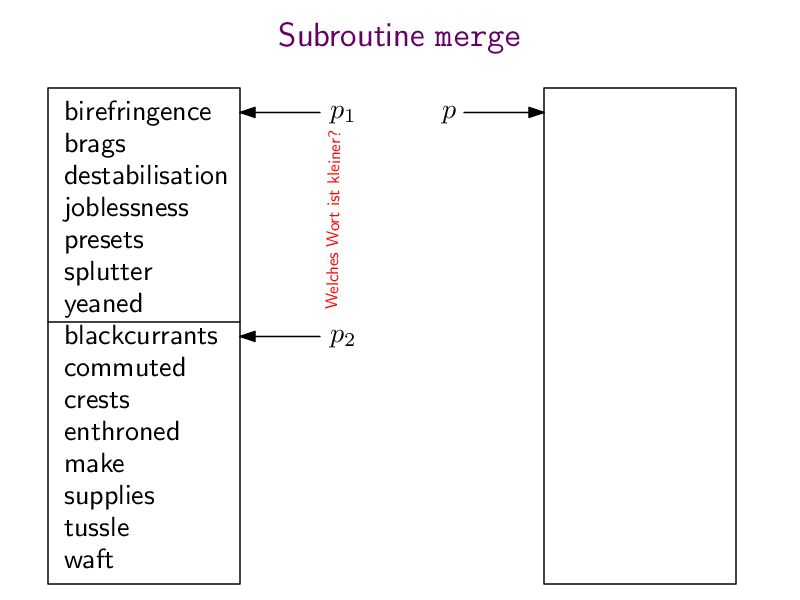
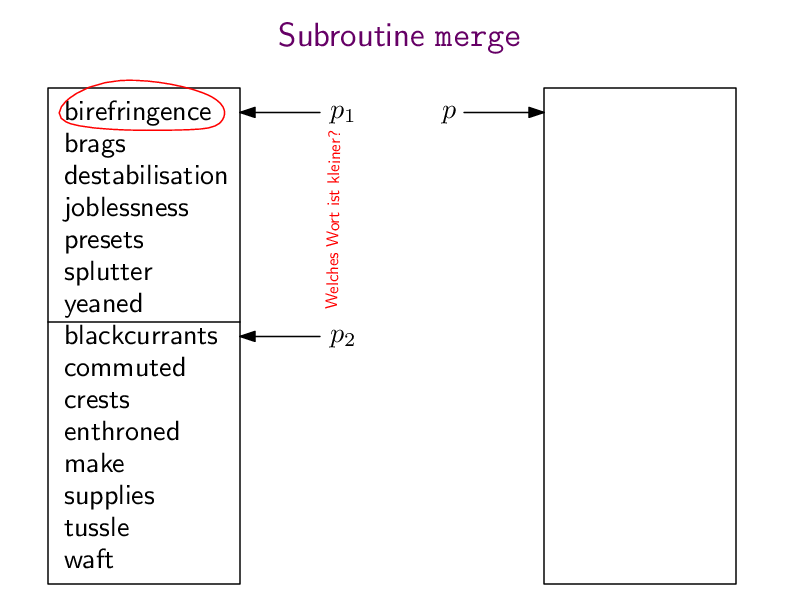
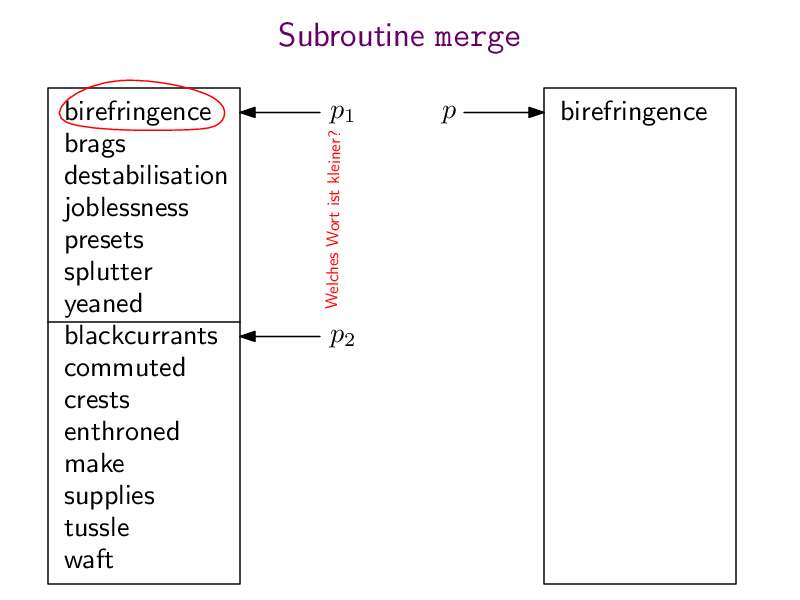
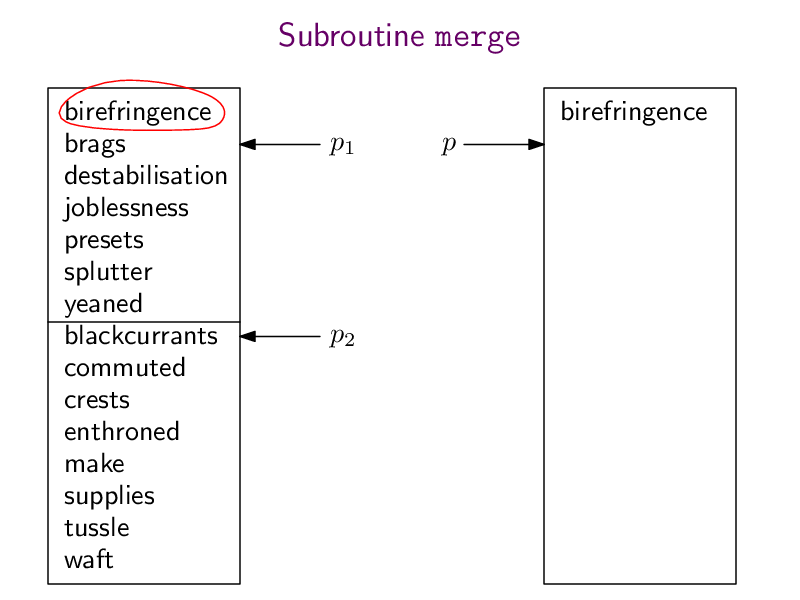

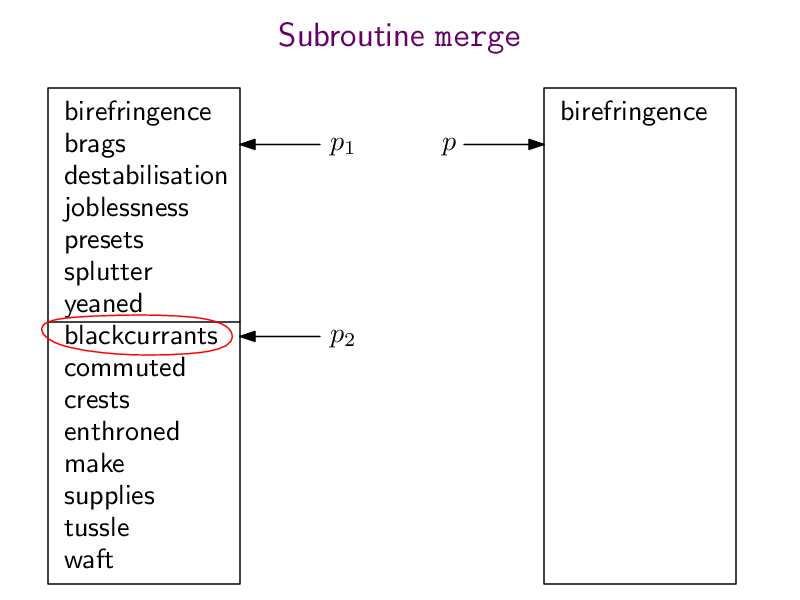
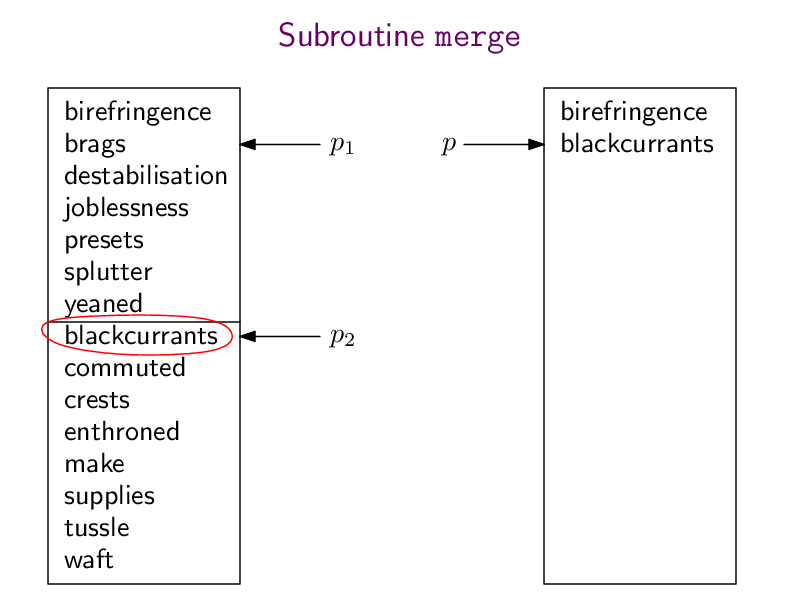
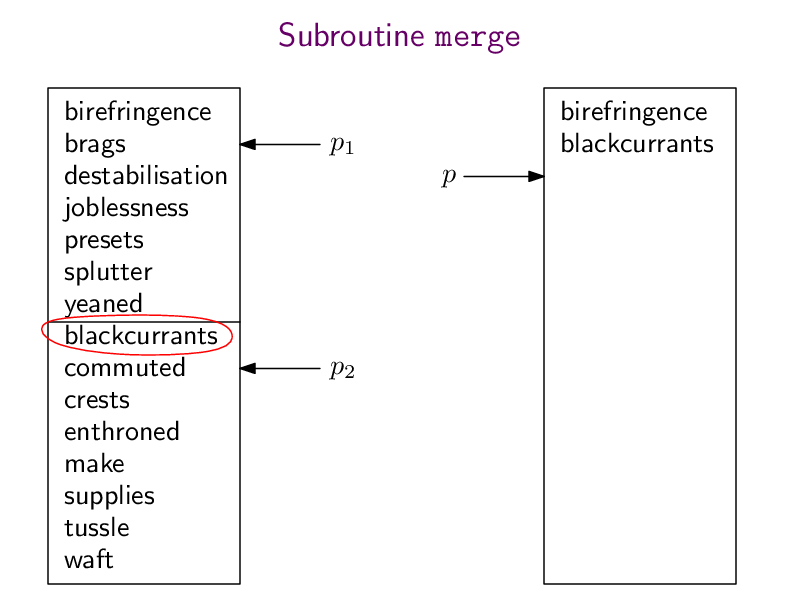








Hier wieder die pdf-Datei mergeSort.pdf mit der ganzen Animation und hier meine Python-Implementierung:
def merge (array1, array2):n1 = len(array1)n2 = len(array2)n = n1 + n2result = [0] * np = 0 # pointer to where to insert the next element into resultp1 = 0 # pointer to where to read the next element of array1p2 = 0 # pointer to where to read the next element of array2while (p < n):if (p2 == n2 or (p1 < n1 and array1[p1] < array2[p2])):result[p] = array1[p1]p1 = p1+1else:result[p] = array2[p2]p2 = p2+1p = p+1return resultdef mergesort(array):if (len(array) < 2):return arraymiddle = len(array) // 2array1 = array[0:middle]array2 = array[middle:]array1 = mergesort(array1)array2 = mergesort(array2)return merge(array1, array2)
Bevor wir die Laufzeit analysiere, sollten wir den Algorithmus experimentell testen. Hierzu brauchen wir wieder folgende Dateien:
- Kopieren Sie den obigen Code in eine Datei
mergeSort.py. In den gleichen Ordner wie diese kopieren Sie bitte - timeMyPrograms.py und
- englishVocabulary.py, falls diese noch nicht in dem Ordner sein sollten.
python3 -i mergeSort.pymeasure_alg (selectionSort, wordlist_unsorted)210.4567011850013 # Laufzeit in Sekundenmeasure_alg (insertionSort, wordlist_unsorted)343.31445141899894 # überraschend, dass es länger dauertmeasure_alg (mergesort, wordlist_unsorted)0.3041463459994702
Der Unterschied zwischen den langsamen Algorithmen SelectionSort und InsertionSort und dem schnellen Mergesort ist gigantisch: Mergesort ist über tausendmal schneller als Insertion-Sort und knapp 700 mal schneller als SelectionSort. Dabei gibt es mehrere Dinge, die oberflächlich gegen Mergesort sprechen:
- Mergesort ist rekursiv. Es wird also Overhead für das Stack-Management geben.
- Mergesort ist nicht in-place: wir vergeben in Zeile 5 von Mergesort neuen Speicherplatz, während Insertion-Sort und Selection-Sort rein auf dem gegebenen Platz von array arbeiten.
Was Sie hier sehen, ist nicht clevere Implementierung. Was Sie sehen, ist ein überlegener Algorithmus.
merge)
führt
merge(array1, array2) im besten und im schlechtesten
Falle durch, in Abhängigkeit von
den Längen von array1 und array2?
Können Sie zu jeden gegebenen Größen
mergesort;
schreiben Sie zu jedem Knoten in diesem Baum, wieviele
Vergleiche der dortige Aufruf von merge durchführt.
mergesort auf einem
Array der Größe
Seien Sie so präzise, wie Sie können! Geben Sie möglichst
genau an, wieviele Vergleiche mergesort
im Worst-Case durchführt.
wordlist_unsorted.
Verwenden Sie timeMyPrograms.py.
Korrektheit und Laufzeit. 2.3.1 Wenn wir einen neuen Algorithmus einführen, dann müssen wir in der Regel zwei Dinge untersuchen:
- Ist der Algorithmus korrekt?
- Welche Laufzeitkomplexität hat er?
In der Tat wird die erste Frage, die nach der Korrektheit, in den ersten Wochen dieses Kurses leicht zu beantworten sein. Für alle Algorithmen bisher war die Korrektheit ziemlich offensichtlich. Dies wird sich in späteren Kapiteln ändern.
Suboptimale Laufzeitanalyse
Lemma 2.3.2
(suboptimal)
Seien
Wie können wir von hier aus die maximale Anzahl von Vergleichsoperationen in einem
Aufruf von mergeSort(array) bestimmen?
Da MergeSort ein rekursiver Algorithmus ist, bietet es sich immer an, seinen Rekursionsbaum
zu skizzieren. Für ein Array der Größe 14 sähe der zum Beispiel so aus:

Jedes graue Rechteck stellt einen Aufruf von mergesort dar, und die
Zahl darin ist die Größe des Arrays bei diesem Aufruf.
Wie wir in Lemma 1.2 gesehen haben, ist die Zahl in dem grauen Rechteck auch eine obere
Schranke für die Anzahl der Vergleiche, die merge macht, um die zwei Teilarrays
wieder zu einem großen zusammenzufügen. Daher:
Beobachtung 2.3.3 Die Anzahl der Vergleiche, die Mergesort tätigt, ist höchstens die Summe der Zahlen in den grauen Rechteckten im Rekursionsbaum.
Gibt es eine einfache Formel für diese Summe? In der Tat:

Sehen Sie: jede "Ebene" des Baumes bis auf die letzte ergibt in Summe 14, also im Allgemeinen
Ebenen. Daher schließen wir nun:
Theorem 2.3.4 Die Anzahl der Vergleiche, die ein Aufruf
von mergeSort auf einem Array der Größe
Optimale Analyse
Wir beginnen mit einer verbesserten Version von Lemma 1.2:Lemma 2.3.5
Seien
Beweis.
Seien
Mit diesem frischen Wissen betrachten wir noch einmal den Rekursionsbaum:

Wie zuvor ist die schwarze Zahl im Rechteck die Größe des Teilarrays; die rote daneben ist eins
weniger und
stellt eine obere Schranke für die Vergleichsoperationen dar, die merge an diesem
Knoten ausführt. Im weiteren sei
- Ebene
len(array) < 2erfüllt ist und Zeile 22 ausgeführt wird. - Die Ebenen
Wir können von nun an Ebene
A ein Array aus mergesort(A)
maximal
Übungsaufgabe 2.3.5
Zeigen Sie, dass Lemma 1.5 optimal ist. Das heißt, zeigen Sie, dass Sie für alle Zahln
merge genau
Die Schranke von merge ist eine obere Schranke.
Für manche Arrays kann es schneller gehen. Um nun zu zeigen, dass auch unsere Analyse von
mergeSort optimal ist, müssen wir ein Array der Länge merge im Rekursionsbaum die maximal mögliche Anzahl
von Vergleichsoperationen nach sich zieht. Jedes Teilarray muss also auch wieder
"so schlimm wie möglich" aussehen.
Übungsaufgabe 2.3.6
Konstruieren Sie Arrays der Länge mergeSort die obere
Schranke von Theorem 1.6 erreicht. Beschränken Sie sich der Einfachheit halber
auf