4. Listen
4.8 Zweites Programmierprojekt: Boolesche Formeln
- Projektvorlage: project-2.zip
- Abgabedatum: Sonntag, der 21. Januar 2024
- Abgabeformat: eine Datei
VornameNachname.elmwie unten beschrieben
Kennen Sie Boolesche Formeln? Dies sind Ausdrücke wie
False und True bzw. 0 und 1. Auch haben wir als
Operatoren nicht
-
Eine Formel
-
-
Als Beispiel nehmen wir die obige Formel
Eine Darstellungsweise, die die "Arbeitsweise" einer Booleschen Formel
Eine induktive Definition für Boolesche Formeln
Beachten Sie, dass eine Boolesche Formel eine Baumstruktur hat.
Unsere Formel

Diese Baumstruktur erlaubt uns, Boolesche Formeln induktiv zu definieren:
Definition 4.8 Die Menge der Booleschen Formeln ist wie folgt induktiv definiert:
-
Eine Konstante wie
-
Eine Variable wie
-
Wenn
-
und auch
-
Wenn
Eine solche induktive Definition ist also wie eine Bauanleitung,
die uns Grundbausteine (hier: Variable und Konstanten) zur Verfügung
stellt sowie Operatoren (hier:

Wir könnten jetzt eine Operatorenpräzedenz à la Punkt vor Strich
definieren. Das würde allerdings erstens alles komplizierter machen und
zweitens uns nicht helfen, zu

Sie könnten jetzt anmerken, dass sei doch das gleiche. Ist es aber strenggenommen nicht. Die zwei Bäume sind andere, auch die "Baugeschichte", also die Reihenfolge, wie wir Punkte 1-5 angewandt haben, um die Formel zu bauen, ist anders. Also: zwei verschiedene Formeln. Äquivalent, aber nicht gleich.
Klammernsetzung. Um Uneindeutigkeiten auszuschließen,
verlangen wir, dass "zusammengesetzten" Formeln
eingeklammert werden, also
Formeln auswerten
Die "Semantik" Boolescher Formeln ergibt sich ja aus den Werten, die
sich ergeben, wenn man den Variablen eine Wahrheitsbelegung gibt.
Wir brauchen also einen Datentyp für Wahrheitsbelegungen. Da gibt
es mehrere Möglichkeiten. Oben haben wir ja bereits
eine Belegung gesehen:
Dies ist also gar kein fertiger Wert. Uns fehlt der Wert von
Wir haben also die Formel erfolgreich ausgewertet, ohne überhaupt für alle Variablen einen Wert gehabt zu haben.
Definition. 4.9 Eine
Belegung wie
Erweitern wir also unseren Horizont. Wenn
- eine Variable
Das Projekt
Endziel dieses Projekts soll eine Web-Anwendung sein, die ungefähr so aussieht:
Ein Elm-Datentyp für Boolesche Formeln und Wahrheitsbelegungen
Wie sollen wir Boolesche Formeln in Elm darstellen? Listen sind ungeeignet, da die "Verschachtelungstiefe" nicht homogen ist. Glücklicherweise lassen sich induktive Definitionen fast wörtlich in eine Elm-Typendefinition übersetzen:
type Formula= Const Bool| Var String| And Formula Formula| Or Formula Formula| Not Formula
Sehen Sie, wie die fünf Alternativen dieser Custom-Typ-Definition
genau den fünf Punkten der induktiven Definition entsprechen?
Die Formel Or (Var "x") (And (Var "y") (Var "z"))
Übungsaufgabe 4.8.1
Laden Sie sich die Projektvorlage
project-2.zip herunter und
entzippen Sie sie.
Stellen Sie sicher, dass project-2 kein
Unterverzeichnis Ihres bereits existierenden Elm-Ordners ist!
Im Verzeichnis project-2 sehen Sie bereits
eine Datei elm.json, einen
Ordner solutions/ und einen Ordner src/.
Letzterer enthält wichtige Typendefinitionen
und den Code, den Herr Schellenberger für Sie bereitgestellt hat, also
zum Beispiel die graphischen Oberflächen. Starten Sie
elm reactor und gehen dann im Browser auf
localhost:8000/src/Main.elm
Sie sehen nun die graphische Oberfläche, allerdings mit einer
Dummy-Implementierung ohne jegliche Funktionalität.
Im Order solutions/ finden Sie die Datei
solutions/DummySolution.elm. Die enthält
das "Gerüst", das Sie nun mit Inhalt füllen müssen. Erstellen
Sie eine Kopie der Datei DummySolution.elm und benennen
Sie sie um in VornameNachname.elm. Öffnen Sie nun
die Datei src/SolutionDispatcher.elm und
ändern Sie sie wie folgt:
module SolutionDispatcher exposing (solution)import VornameNachname-- import DummySolutionsolution =VornameNachname.solution --DummySolution.solution
Jetzt weiß die App src/Main.elm, dass Sie
"Ihre" Lösung verwenden soll. Jede Änderung in der Datei
solutions/VornameNachname.elm wirkt sich jetzt
auf das Verhalten der App aus. Probieren Sie's aus:
ändern Sie die Variable name und laden die App-Seite
neu.
Sehen Sie: auch das "Bündeln" Ihrer Funktionen im
Record-Type type alias Solution = { ... },
dass Sie auf meine Bitte im ersten Projekt nachgeholt haben,
habe ich hier bereits übernommen.
Wenn Sie Ihr Projekt abgeben wollen, müssen Sie also nur eine
einzige Datei verschicken: VornameNachname.elm.
Nebenbemerkung: eigentlich ist es kein guter Stil, alles in eine Datei zu schreiben. Für das Projekt hier ist es aber am Einfachsten.
Testataufgabe 4.8.2
Implementieren Sie
die Funktion toString, die eine Formel in
einen String codiert, wobei wir
das &, das |
und das ! schreiben.
f = Or (Var "x") (And (Var "y") (Var "z"))Or (Var "x") (And (Var "y") (Var "z")) : FormulaBooleanFormulas.toString f"(x | (y & z))" : String
Da eine Wahrheitsbelegung manchen Variablen einen Wert zuweist, aber nicht allen,
könnten wir sie als List (String, Bool) darstellen. Die
Belegung [("x",True), ("y", False)]. Diese Darstellung hat allerdings
zwei Nachteile. Erstens sind nun
[("x",True), ("y", False)] und
[("y", False), ("x",True)] in Elm zwei verschiedene Dinge,
obwohl sie doch die gleiche Belegung darstellen. Zweitens
stellen Sie sich vor, dass wir es mit einer Formel mit tausenden von
Variablen zu tun haben (kommt in der Praxis tatsächlich vor).
Jedes Mal, wenn Sie wissen wollen, welchen Wert "x" hat,
müssen sie die Liste durchgehen, im schlimmsten Fall bis zum Ende.
Was wir brauchen, ist eine Dictionary-Datenstruktur. Eine solche
erlaubt es uns, Schlüssel-Wert-Paare zu speichern und schnell abzufragen.
In Java gibt dafür zum Beispiel die Klasse Hashtable.
In Elm gibt es den Datentyp Dict:
import Dictd = Dict.fromList [ ( "Montag", 1 ), ( "Dienstag", 2 ), ( "Mittwoch", 3 ), ( "Donnerstag", 4 ), ( "Freitag", 5 ), ( "Samstag", 6 ), ( "Sonntag", 7 ) ]Dict.get "Donnerstag" dJust 4Dict.get "Friday" dNothing
Mit dem Wert Nothing teilt uns das Dictionary mit, dass es
zum Schlüssel "Friday" keinen entsprechenden Wert gibt.
Für Wahrheitsbelegungen brauchen wir also ein
Dictionary, dass als Schlüssel Strings nimmt (Variablennamen)
und als Werte Boolesche Werte. Also:
belegung = Dict.fromList [("x",True),("y",False)]Dict.fromList [("x",True),("y",False)] : Dict.Dict String Bool
Der Datentyp ist also Dict String Bool. Das Repl-Fenster sagt
uns Dict.Dict, weil der Typ Dict in einem
Modul Dict definiert ist. Wenn Sie das stört, können
Sie den Datentyp exposen, dann "kennt" die Laufzeitumgebung diesen
beim Namen:
import Dict exposing (Dict)Dict.fromList [("x",True),("y",False)] : Dict String Bool
Es ist in Elm durchaus üblich, Modul und Datentyp gleich zu benennen.
Und beim benutzen dann den Namen des Typs zu exposen, also
import Dict exposing (Dict).
Testataufgabe 4.8.3
Implementieren Sie die Funktion evaluate, die
eine Boolesche Formel unter einer gegebenen Wahrheitsbelegung
auswertet:
belegung = Dict.fromList [("x",False),("y",True)]f = Or (Var "x") (And (Var "y") (Var "z"))evaluate f belegungVar "z" : Formulaevaluate f (Dict.fromList [("x", True), ("y", False)])Const True : Formula
Wahrheitstabellen
Jetzt wollen wir für eine gegebene Formel automatisch eine Wahrheitstabelle ausrechnen, also wie die hier:
Welcher Datentyp ist hierfür geeignet? Eine Zeile
in der Wahrheitstabelle besteht aus einem linken Teil
und einem rechten Teil. Der linke Teil ist
die Belegung, der rechte Teil der sich ergebende Wert, also
das Ergebnis von evaluate.
In Wahrheitstabellen listen wir zwar üblicherweise
alle totalen Belegungen auf. Es spricht allerdings
nichts dagegen, nur einen Teil der Variablen zu verwenden;
dann hätte man links nur partielle Belegungen und rechts
eventuell Formeln statt konstante Werte. Wenn wir für
Formel
Ein Eintrag in der Wahrheitstabelle
könnte also vom Datentyp
(Dict String Bool, Formula) sein.
Allerdings will ich hier kein Dict verwenden:
eventuell wollen wir ja die Reihenfolge der Variablen
ändern, also beispielsweise
(List (String, Bool), Formula)
darstellen und die ganze Tabelle dann als
List (List (String, Bool), Formula).
Testataufgabe 4.8.4
Implementieren Sie die
Funktion getAllVariables: Formula -> List String , die Ihnen
die Liste aller Variablen, die in der Formel vorkommen, liefert.
Tip: um sicherzustellen, dass keine Variable in der
Liste doppelt vorkommt, empfehle ich Ihnen, die Datenstruktur
Set zu verwenden:
import Set exposing (Set)set1 = Set.fromList ["x", "y", "z"]set2 = Set.fromList ["y", "v"]Set.union set1 set2Set.fromList ["v","x","y","z"] : Set String
Die Datenstruktur sorgt also dafür, dass das "y" nicht
doppelt vorkommt. Mit Set.toList erhalten
Sie wieder eine Liste:
Set.toList (Set.union set1 set2)["v","x","y","z"] : List String
Testataufgabe 4.8.5
Implementieren Sie
die Funktion getAllAssignments : List String ->
List (List (String, Bool)), die Ihnen eine Liste
aller Wahrheitsbelegungen auf diesen Variablen liefert:
getAllAssignments ["x", "y"][[("x",False),("y",False)],[("x",False),("y",True)],[("x",True),("y",False)],[("x",True),("y",True)]] : List (List ( String, Bool ))
Tip: der Code ist ähnlich wie
der von powerSet im vorherigen Kapitel.
Testataufgabe 4.8.6
Implementieren Sie die Funktion generateTruthTable:
die die Wahrheitstabelle einer Formel berechnet und dafür alle partiellen Belegungen übergenerateTruthTable : String List -> Formula -> List (List (String, Bool), Formula)generateTruthTable variables formula =...
variables
auflistet.
Formeln einlesen
Bereits oben haben wir einen Datentyp Formula definiert, und
Sie haben eine Funktion toString implementiert. Für unsere App
ist nun aber die Umkehrfunktion interessanter: einen String in eine Formel
zu decodieren. Das könnte in etwa so aussehen:
stringToFormula "(x | ((!y) & z))"Or (Var "x") (And (Not (Var "y")) (Var "z"))
Was Sie hier sehen, ist eine fundamentale Aufgabenstellung in der Informatik: einen String in ein sinnvolles Objekt zu übersetzen. Am Anfang ist ja alles ein String: Benutzer-Eingaben, Daten, die über ein Netzwerk gesendet werden, Inhalte einer Datei etc. Wenn Sie zum Beispiel im Elm-Repl-Fenster einen Ausdruck eingeben:
if (3 < 5) then (True,3) else (False, 6)
dann sieht der Elm-Interpreter erst einmal einfach den String
"if (3 < 5) then (True,3) else (False, 6)", also im Prinzip
eine Liste von Characters. Der Elm-Integerpreter muss jetzt die logische Struktur
dieses Strings erkennen: es ist ein if-Ausdruck; die Bedingung ist
3 < 5, der then-Wert ist (True,3), was
ein Tupel aus einem Bool und einem number ist, und so weiter.
Wir müssen also aus dem String - einer Zeichenkette mit linearer Struktur - ein
Objekt, häufig etwas Baumförmiges, bauen, das die logische Struktur des Strings widerspiegelt.
Man nennt dies Parsing. Sie müssen in diesem Teil also einen Parser schreiben,
der einen String in eine Boolesche Formel umwandelt.
Der Benutzer soll auf der Web-App eine
Boolesche Formel eingeben kann, also zum Beispiel (x & (! y)),
und die Web-App zeigt dann die Formel als Bäumchen an, berechnet die
Wahrheitstabelle etc.
Machen wir uns als erstes Gedanken über die Signatur des Parsers.
parse : String -> Formula, ist doch klar, oder? Naja,
wenn Sie mit Benutzerinput arbeiten, dann müssen Sie damit rechnen, dass
der Input fehlerhaft ist, beispielsweise
x & (y | z) (hier fehlen die äußeren Klammern) oder
x & | y oder sogar ganz Unsinnges wie {x/\ &y}.
Sie müssen also damit rechnen, dass es einen Parse Error gibt, wenn
der String nicht im richtigen Format ist. Also
parse : String -> Result ParseError Formula
Result ist ein Datentyp definiert als
type Result a b = Err a | Ok b, der also einen
"Erfolgstyp" und einen "Fehlertyp" vereint.
Das Format. Wir müssten nun als erstes ein Format für unsere Formeln
definieren. Das haben wir ja irgendwie bereits getan. Wir könnten sagen, "alles, was
toString zurückliefert, ist ein gültiger String. Dann könnten
Sie allerdings dummes Zeug machen wie
f = Or (Var "(") (Var "|")toString f"(( | |)" : String
Schlimmer noch: Sie könnten einer Variable einen Namen geben, der selbst wieder aussieht wie eine Formel:
g = Or (Var ("(a & b)")) (Var "y")toString g"((a & b) | y)" : String
Die Funktion toString ist nicht eineindeutig: die zwei
verschiedenen Instanzen von Formula, nämlich
Or (Var ("(a & b)")) (Var "y")
und Or (And (Var "a") (Var "b")) (Var "y") ergeben
den gleichen String, nämlich "((a & b) | y)".
Wir haben jetzt im Prinzip zwei Möglichkeiten: entweder, wir
ändern die Codierung, indem wir beispielsweise alle Variablennamen
in Anführungszeichen setzen:
toStringWithQuotes (Or (Var ("(a & b)")) (Var "y"))"(('a' & 'b') | 'y')" : StringtoString (Or (Var ("(a & b)")) (Var "y"))"('(a & b)' | 'y')" : String
Jetzt müssen Sie aber wieder aufpassen: Spaßvögel (oder Angreifer) fügen eventuell Single-Quotes in die Variablennamne mit ein:
toString (Or (Var ("a' & 'b")) (Var "y"))"('a' & 'b' | 'y')" : String
Sie könnten das umgehen, indem Sie Escape-Characters verwenden, also
statt ' und " in Ihren Output-String
die Kombination \' bzw. \" schreiben;
und statt \ die Kombination \\. Man nennt
dies auch "Input Sanitization". Der Web-Comic xkcd hat hierzu folgende Illustration:
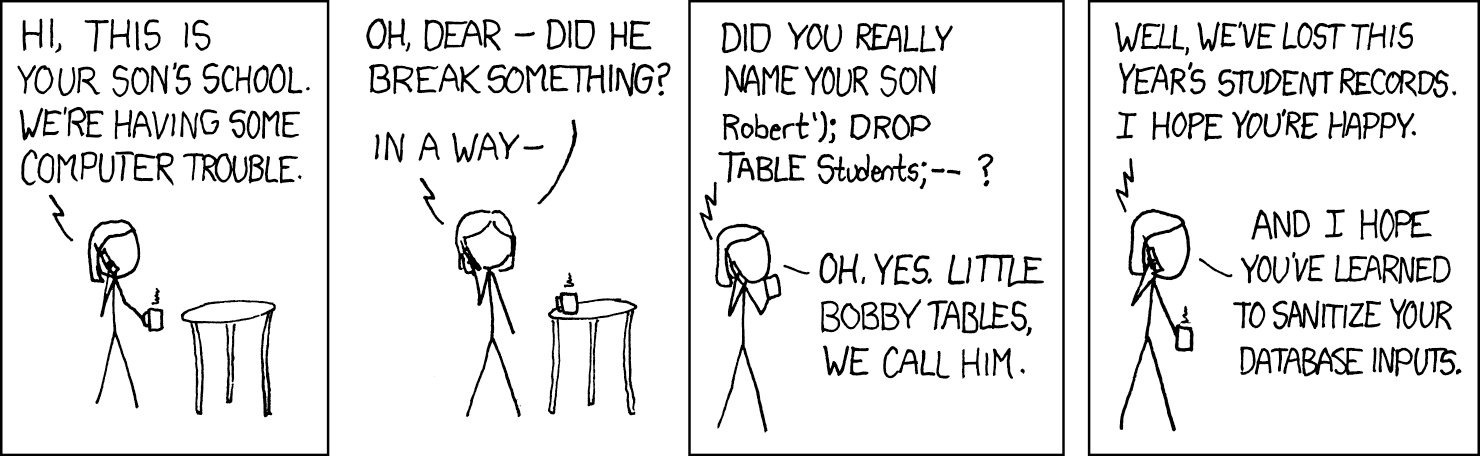
Auch wenn ein deutsches Standesamt Ihnen wohl nicht erlauben würde, Ihr Kind "Robert'); DROP TABLE Students; --" zu nennen, wäre ich mir bei den Kindern gewisser amerikanischer Unternehmer nicht so sicher; und wenn schon nicht das Standesamt, dann erlaubt mir vielleicht die Webseite, einen solchen Namen einzugeben.
In dieser Anwendung wählen wir einen anderen Weg, der auch bei Programmiersprachen üblich ist:
wir führen strenge Regeln ein, wie ein Variablenname aufgebaut sein darf, beispielsweise
eine beliebige Kombination alphanumerischer Zeichen, also a-z, A-Z, 0-9 sowie
dem
Sonderzeichen _, wobei das erste Zeichen ein Buchstabe sein muss.
Also: "x_1" und "x___1_2" ja, aber
"1_" und "_x" nein, und schon gar nicht
"x & y" oder "(x & (y | z))".
Als erstes brauchen wir nun eine Funktion, die den Eingabestring, also
sowas wie "((a_1 & 0) | y)", in lexikalische Bestandteile
zerlegt, also etwa
["(", "(", "a_1", "&", "0", ")", "|", "y" ")"] oder
am Besten sogar schon ein bisschen Syntax erkennt, also dass es sich
bei & um einen Operator, bei a_1 um eine Variable,
bei 0 um eine Boolesche Konstante und bei "(" um eine öffnende
Klammer handelt. Solche lexikalischen Einheiten nennt man Tokens. Hier
sehen Sie meinen Datentyp BoolToken:
type BoolToken= CONST Bool| VAR String| AND| OR| NOT| OPEN| CLOSE
Ein String wie "((a_1 & 0) | y)" entspräche nun also der Tokenliste
[OPEN, OPEN, VAR "a_1", AND, CONST False, CLOSE, OR, VAR "y", CLOSE]
Diesen Prozess, einen Eingabestring in lexikalische Tokens zu zerlegen, nennt man
Lexing. Eine Implementierung, die das tut, nennt man Lexer.
Beachten Sie, dass ein Lexer wirklich nur lokal arbeitet und keine größeren Strukturen
erkennt. Strings wie "x & | y_2 (!)" würde er anstandlos
in die Tokenliste
[VAR "x", AND, OR, VAR "y_2", OPEN, NOT, CLOSE] zerlegen.
Die Implementierung des Lexers hat Herr Schellenberger für uns erledigt. Sie müssen nur die Funktion aufrufen:
BooleanLexer.lex<function> : String -> List BoolTokenBooleanLexer.lex "x & | y_2 (!)"[VAR "x", AND, OR, VAR "y_2", OPEN, NOT, CLOSE]BooleanLexer.lex "((a_1 & 0) | y)"[OPEN, OPEN, VAR "a_1", AND, CONST False, CLOSE, OR, VAR "y", CLOSE]
Die Syntax, die Herrn Schellenbergers Lexer akzeptiert, ist übrigens nicht so streng wie meine
oben geschilderte: als Variablennamen ist alles erlaubt außer Whitespace (Leerzeichen, Tab, neue
Zeile) und
den syntaktisch bedeutsamen Zeichen ( ) & | !.
Einen Parser schreiben
Um nun einen Parser zu entwerfen, beschreibe ich erst einmal formal die Syntax unserer Formeln als Folge von Lex-Tokens. Ich tue dies mit einer formalen Grammatik (mehr dazu in der Veranstaltung Theoretische Informatik). Eine formale Grammatik beschreibt eine Syntax als Menge von Bildungsgesetzen. In unserem Falle steht jedes Bildungsgesetz für einen Punkt in der induktiven Definition 4.8:
Wie können wir nun eine Liste von Lextokens in eine Formel überführen? Die Idee ist, dass wir die Tokens Stück für Stück auf einen Stapel, den Stack legen, bis wir ein Muster erkennen, das einem der sechs Bildungsgesetze entspricht. Dann fassen wir diese Stücke dieses Musters zu einer Formel zusammen. Der Stack schrumpft dann also. Hier sehen Sie es als Klick-Animation:






















Wir brauchen für unseren Parser also zwei Dinge: ersten die Tokenliste, die uns
der Lexer von Herrn Schellenberger ja bereits liefert; zweitens einen Stack,
auf den wir die Tokens legen oder, falls wir ein Bildungsgesetz erkannt haben,
mehrere Stack-Elemente in eine Formel zusammenfassen. Der Stack soll also
sowohl Elemente vom Typ BoolToken als auch vom Typ
Formula enthalten. Das geht in Elm natürlich nicht. Sie
brauchen also einen weiteren Datentyp (der bereits in src/Types.elm
definiert ist):
type StackElement= Formula Formula| Token BoolToken
Testataufgabe 4.8.7
Implementieren Sie in solutions/VornameNachname.elm eine Funktion
parseStep : BoolToken -> List StackElement -> List StackElementparseStep token stack = ...
die einen Schritt des Parsers ausführt. Das heißt, sie überprüft, ob
das neue token zusammen mit den letzten stack ein Bildungsgesetz bildet, in welchem Fall es diese Elemente
vom Stack nimmt und eine neu gebildete Formel oben (vorne) drauflegt;
falls es kein Bildungsgesetz entdeckt, legt es, wie wir in unserer Animation,
das neue Token einfach oben auf den Stack.
Ein Bildungsgesetz erkennt es beispielsweise, wenn das neue Token
ein VAR "x" ist. Dann muss es nun die Formel
Var "x" oben auf den Stack legen. Dafür muss die
Formel erst einmal als StackElement verpackt werden. Ihre
Funktion parseStep müsste also irgendwo den Code
Formula (Var "x") :: stack ausführen. Es hat also den
Token erfolgreich in eine Formel umgewandelt.
Spannend wird es, wenn das neue token den Wert
CLOSE hat. Dann sollte der neue Token, zusammen mit den obersten
paar Werten auf stack einem der drei letzten Bildungsgesetze entsprechen,
und Sie müssen dementsprechend eine neue Formel bauen und auf den Stack legen.