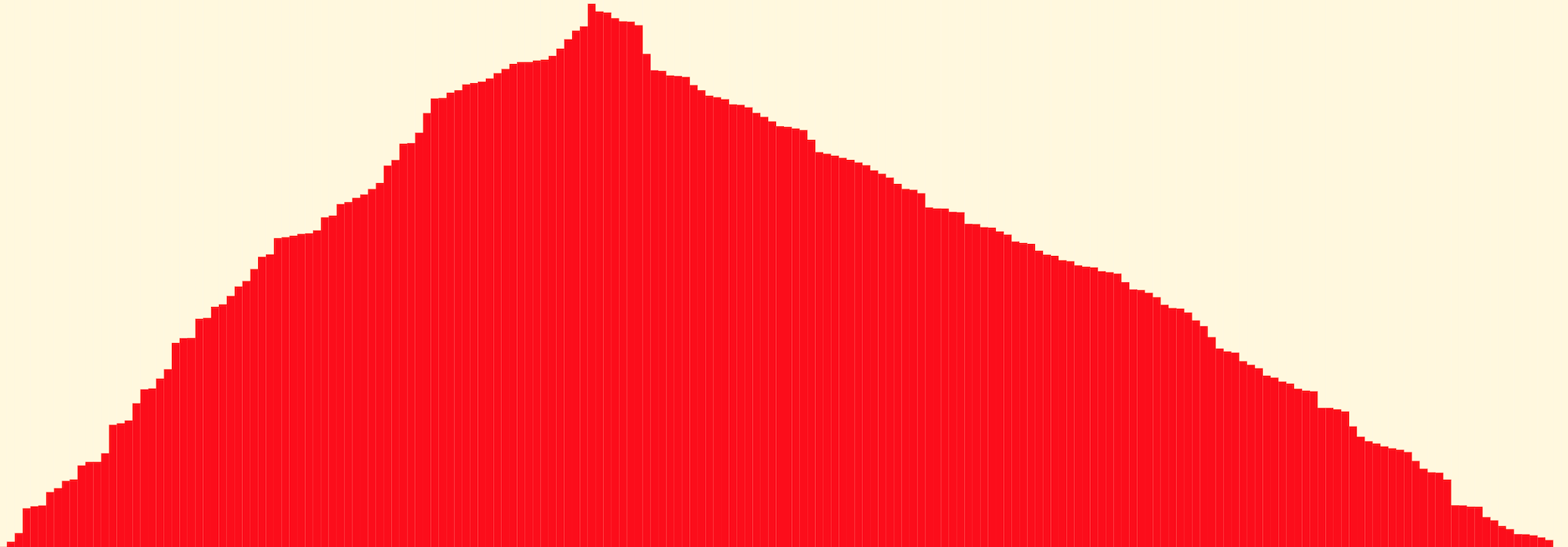
Eine Zahlenfolge heißt unimodal, wenn es ein gibt
mit
Bildlich gesprochen, wenn die Werte erst bis zu einem Maximum ansteigen und
danach wieder abfallen. Salopp gesprochen, wenn die Folge ungefähr so aussieht:
Betrachten wir nun das Optimierungsproblem, das Maximum eines unimodalen
Arrays mit Elementen zu finden. Natürlich können wir dies mit
linearer Suche erreichen, müssten dafür im schlimmsten Fall wieder alle Positionen
durchtesten.
Demo 1.3.2
Auf
maximize-unimodular-function.html
können Sie interaktiv versuchen, das Maximum einer unimodalen Folge mit möglichst wenig
Versuchen zu finden.
Theorem 1.3.3(binäre Suche auf unimodalen
Arrays)
Sei ein unimodales Array mit Elementen. Wir können das Maximum
mit höchstens Array-Zugriffen finden.
Beweis.
Sei ein Array aus Elementen, definiert als
misst sozusagen die "Steigung" von . Beachten Sie, dass nicht notwendigerweise
sortiert ist. Allerdings gilt: wenn das Maximum von bei liegt,
dann ist negativ für alle
und positiv für alle . Wir suchen also das erste positive
Element in und können dies mittels binärer Suche mit maximal
Zugriffen auf das Array finden.
Ein Problem ist nur, dass wir ja bereits Zugriffe auf brauchen, um
überhaupt erst berechnen zu können. Die entscheidende Einsicht ist hier,
dass wir nicht explizit berechnen müssen: nein, erst wenn der Algorithmus den
Wert abfragt, schlagen wir und nach und
geben zurück. Pro -Zugriff benötigen wir also zwei -Zugriffe.
Demo 1.3.4
Für zum Beispiel würde obiger Algorithmus im schlimmsten Falle
Zugriffe tätigen. Ich behaupte, man kann mit maximal
9 Zugriffen das Maximum bestimmen.
Übungsaufgabe 1.3.1
Üben Sie in Paaren die Maximierung unimodaler Arrays als Spiel:
Alice stellt fragen der Form Was ist A[i] und Eve
antwortet mit einem Wert (zum Beispiel einer reellen Zahl).
Eve muss konsistent antworten, d.h., das Sub-Array aus beantworteten
Fragen muss selbst unimodal sein.
Alices Ziel ist es, mit möglichst wenig Fragen das Maximum zu finden;
Eve will dies hinauszögern. Spielen Sie es zu zweit mit verteilten Rollen.
Achten Sie darauf, welche Strategien für Alice und Eve offensichtlich gut bzw.
offensichtlich schlecht sind.
Wir können präzise charakterisieren, wieviele Array-Zugriffe man im schlechtesten Fall
benötigt, um das Maximum eines unimodalen Arrays des Länge zu finden.
Die exakte Formel ist leider weniger griffig als beispielsweise
. Es lohnt sich, dieses Problem rigoros zu analysieren, erstens weil
Sie hier einen mathematischen Beweis in seiner ganzen Pracht sehen werden;
zweitens, weil man daran gut demonstrieren kann, wie man in der Praxis
"auf mathematische Beweise kommt", sie also findet, auch wenn man anfangs völlig ahnungslos ist.
Es ist also ein exzellentes Beweis für mathematische Beweisführung und auch
Beweisfindung
Ich werde im Verlauf der Analyse
wichtige Stationen mathematischer Beweisfindung fettgedruckt hervorheben.
Maximum in einem unimodalen Array finden - Eine genaue
Analyse.
Stellen Sie sich vor, Sie beobachten ein das oben beschriebene Spiel zwischen Alice und Eve
und pausieren zu einem bestimmten Zeitpunkt. Alice hat also bestimmte Indizes
in angefragt und Eve hat geantwortet (es wird nun vorteilhaft sein,
die Array-Indizes von bis laufen zu lassen).
Stellen Sie die richtigen Fragen. In diesem Falle:
Egal ob Alice und Eve im bisherigen Verlauf optimal gespielt haben oder nicht,
wieviele weitere Zugriffe benötigt Alice, wenn ab jetzt beide optimal spielen?
Sehen Sie insbesondere, dass die gerade gestellte Frage komplexer ist als
die, wieviele Zugriffe Alice bei einem Array der Länge braucht; sie ist komplexer,
weil die Antwort eben nicht nur von abhängt, sondern auch vom bisherigen Spielverlauf.
Paradoxerweise werden Fragen oft einfacher zu beantworten, wenn man sie (auf die richtige
Weise)
verallgemeinert und dadurch scheinbar komplexer macht.
Welche Information brauchen Sie?
Zur Beantwortung der oben gestellten Frage brauchen wir als Information die Länge des
Arrays
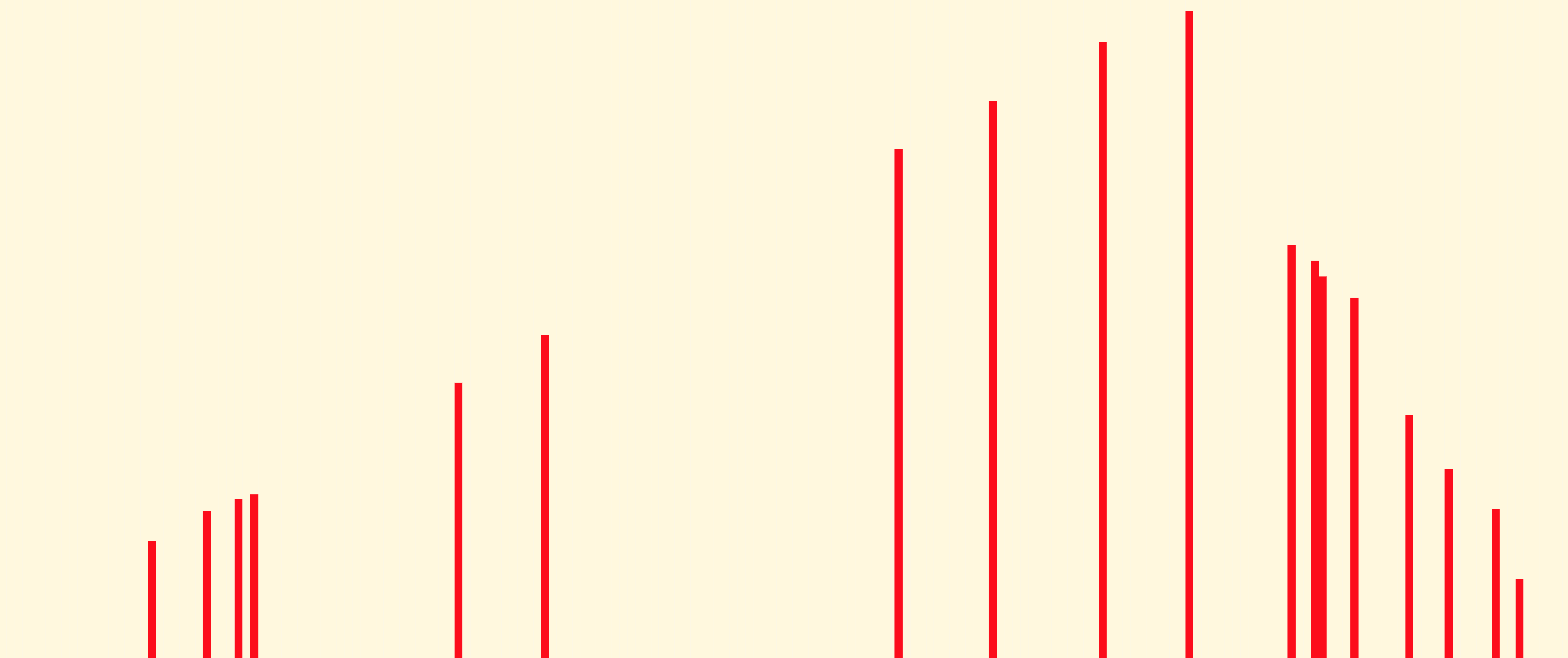
und den bisherigen Spielverlauf. Also zum Beispiel
Warten Sie! Enthält obiges Bild wirklich die gesamte Information, um den Spielverlauf zu
rekonstruieren?
Nein! Hierfür bräuchten wir die zeitliche Abfolge der Anfragen. Eine vollständige
Beschreibung
des Spielverlaufs wäre also eine Folge von Indizes
welche die von Alice gestellten Anfragen darstellt, zusammen mit einer Reihe von reellen
Zahlen
welche Eves Antworten darstellen, sodass und
die Folge selbst unimodal ist.
Das obige Bild stellt dies fast dar, allerdings nur fast, da es die
Reihenfolge
ignoriert. Müssen wir aber die Reihenfolge überhaupt kennen, um die Frage zu beantworten:
Wieviele weitere Zugriffe benötigt Alice, wenn ab jetzt beide optimal spielen?
Für die Beantwortung dieser Frage ist die Reihenfolge, in welcher Alice die in der
Vergangenheit
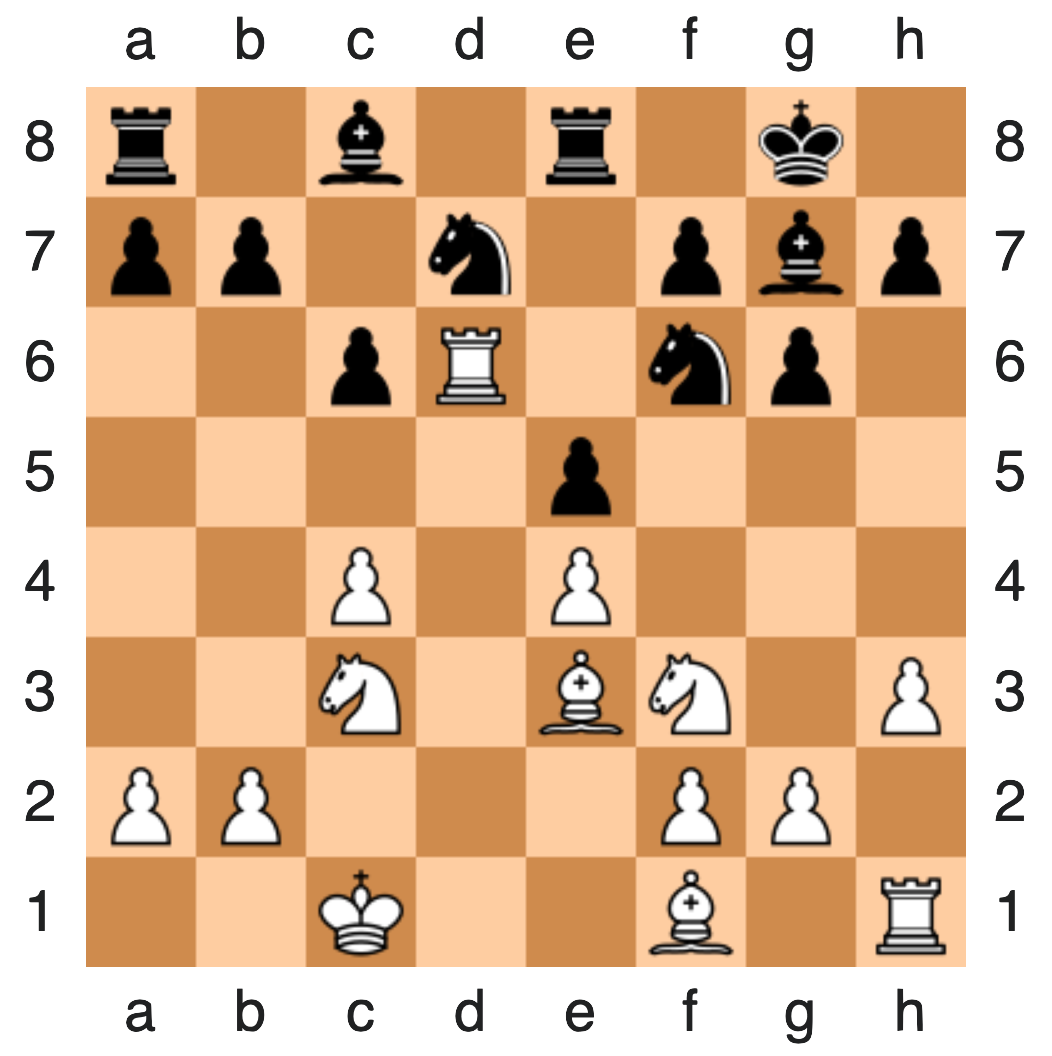
liegenden Zugriffe getätigt hat, irrelevant. Vergleichen Sie es mit einem Schachspiel:
Tarrasch vs. Euwe, Bad Pistyan (1922). Quelle:
Wikipedia
Um zu entscheiden, welcher Zug für Weiß nun optimal ist, ist es irrelevant,
wie Tarrasch und Euwe zu dieser Position gelangt sind. Wichtig ist einzig und allein
die Position. Daher: ja, das obige Bild mit den roten Balken ist ausreichend,
um unsere Frage zu beantworten.
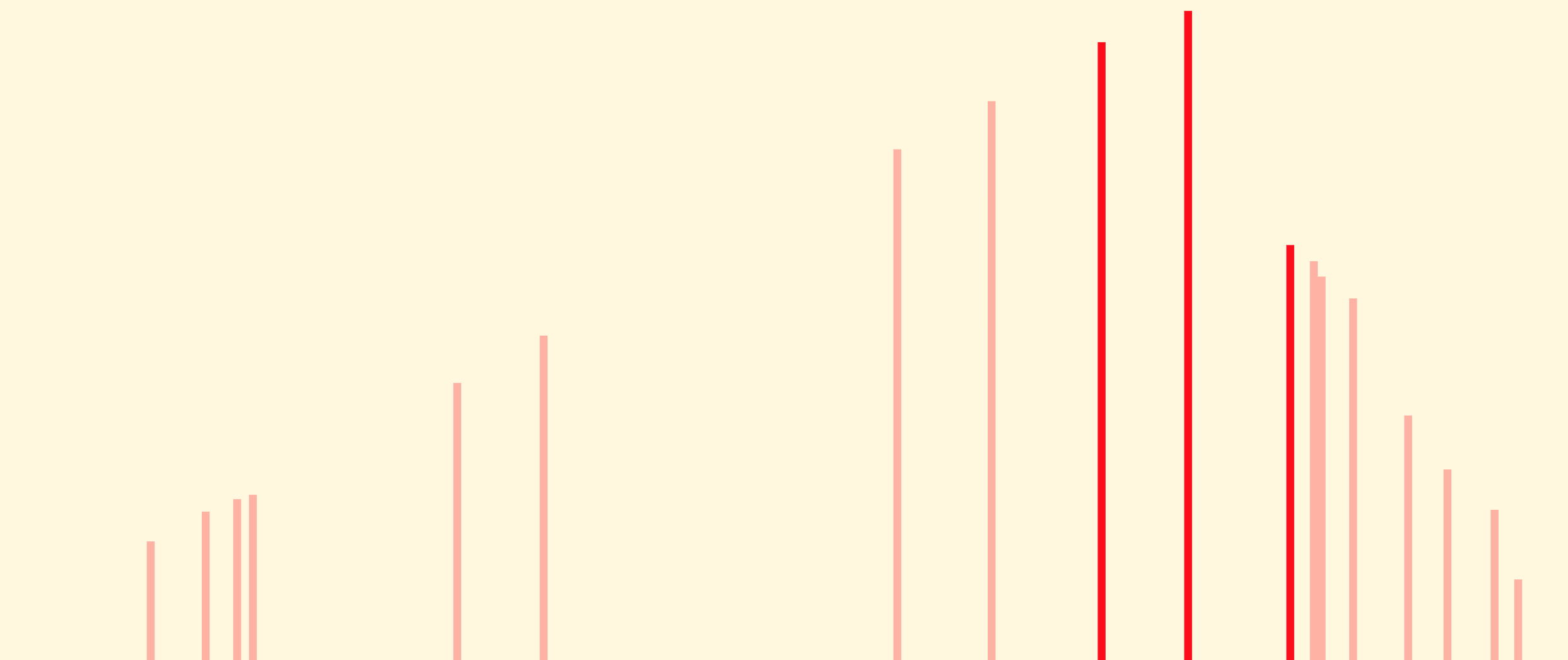
Es ist sogar zuviel Information. Ich behaupte, wichtig sind allein die
im unteren Bild stark roten Balken; die blassen können wir ignorieren:
In der Tat: das Maximum liegt sicherlich innerhalb der drei stark roten Balken.
Eine optimal spielende Alice wird von nun an nie mehr außerhalb dieses Bereichs auf das
Array zugreifen. Wir können also die blass roten Balken vergessen und uns nur
die Position und Höhe der stark roten merken:
Im nächsten Schritt wird Alice einen Index zwiscehn und anfragen
und die Antwort mit vergleichen. Alice muss sich also nicht nur
die Positionen merken, sondern auch die Werte des Arrays
an diesen Positionen. Für die Beantwortung der Frage
Wieviele weitere Zugriffe benötigt Alice? spielen die genauen Werte allerdings
keine Rolle! Für einen optimalen Spielverlauf ist nur die Ordnung der Werte
entscheidend (also welche größer und welche kleiner sind als andere); da Eve mit reellen
Zahlen spielt, kann sie sicherlich immer eine weitere Zahl zwischen zwei gegebenen finden.
Wir stellen also fest: um den optimalen weiteren Spielverlauf zu bestimmen, sind
die genauen Werte irrelevant; wir müssen nur kennen und natürlich wissen,
dass
gilt. Ja nicht einmal müssen wir uns merken. Kenntnis der natürlichen Zahlen und
reicht völlig aus, um die optimale Anzahl weiterer Zugriffe zu bestimmen.
Reduzieren Sie Information! Die Antwort auf die Frage
Wieviele weitere Zugriffe benötgit Alice, wenn von nun an beide optimal spielen?
hängt nur von den Zahlen
und ab.
Führen Sie neue Notation ein! Definieren wir als die
Anzahl von weiteren Zugriffen, die Alice benötigt, um das Maximum der unimodalen Funktion zu
bestimmen,
wenn beide optimal spielen und gilt. Wie oben argumentiert,
hängt das nicht
von ab, wir können also statt schreiben.
Erinnern wir uns an die ursprüngliche Frage: wieviele Zugriffe brauchen wir, um
das Maximum eines unimodalen Arrays zu finden? In diesem Szenario
gibt es kein und kein , da Alice noch gar keine Fragen gestellt hat.
Sei also der erste Index, den Alice anfragt.
Da per Konvention gilt, haben wir
und können nun setzen und wissen, dass Alice von nun an
(wenn beide optimal spielen) weitere Zugriffe benötigt. Um die Gesamtzahl
zu minimieren, muss Alice den Parameter optimieren und benötigt daher insgesamt
Zugriffe. Das beszieht sich auf den ersten Zugriff, den auf den Index . Wenden
wir uns nun wieder unserer Funktion zu und versuchen, sie zu verstehen.
Sammeln Sie einfache Fakten. Was wissen wir über ?
Nun, zum Beispiel . Klar: wenn und , dann liegt
das Maximum des Arrays beim Index ; keine weiteren Fragen nötig.
Links-Rechts-Symmetrie: . Die Komplexität ändert sich nicht,
wenn wir Array und angefragte Indizes einfach von rechts nach links umkehren.
Monotonie: . Klar: größere Intervalle können es für Alice
nicht einfacher machen.
Spielen Sie selbst! Lassen Sie uns kurz in die Rollen von Alice und Eve
schlüpfen. Angenommen, Alice fragt einen Index an mit :
Eves Antworten fallen in zwei Kategorien. Entweder ist
oder .
Wie soll Eve nun antworten?
Falls gilt, dann
können wir von nun an vergessen und mit den drei Indizes
weiterspielen. Alice benötigt also
noch weitere Zugriffe.
Fals gilt, dann können wir
vergessen und mit den Indizes weiterspielen.
Alice benötigt also noch weitere Zugriffe.
Wie sollte Eve also antworten? In jedem so, dass sie das
größere von und bekommt.
Wegen unseren "einfachen Fakten" Links-Rechts-Symmetrie und Monotonität gilt nun
In Worten: Alice hat zwei Intervalle mit Längen .
Durch den Zugriff auf zerlegt Alice
das erste Intervall und erhält somit drei Intervalle mit Lägen .
Eve kann sich nun entscheiden, ob das Spiel auf den ersten beiden Intervallen
fortgesetzt wird, also oder auf den letzten beiden, also .
Welche Entscheidung optimal ist, hängt nur davon ab, ob oder größer ist.
Ein Spielzug lässt sich nun also wie folgt darstellen:
Gegeben ein Paar , zum Beispiel , zerlegt Alice
die erste Zahl und erhält ein Tripel, zum Beispiel: .
Eve kann sich nun für das erste Paar oder das zweite
Paar entscheiden und nimmt natürlich das "größere", hier also .
Als Tabelle:
Alice zerlegt in:
Eve wählt als neues Paar:
oder , spielt keine Rolle
Es sollte klar sein, dass die letzten drei Zeilen für Alice suboptimal sind, da
wegen Monotonie gilt. Alice
darf also in zerlegen, wie sie will, sollte
aber tunlichst wählen. Was haben wir aus unserem Beispielzug gelernt?
Doch halt! Wir haben etwas vergessen! Alice kann natürlich auch
anfragen, also das rechte Intervall zerlegen:
Alice zerlegt das rechte Interval und erhält drei Intervalle
mit Längen . Welches Paar wählt Eve? Das hängt davon ab, ob
oder größer ist. Führen wir eine Konvention ein:
, das linke Interval ist mindestens so groß wie das rechte; so
sieht es auf den Bildern ja auch aus. Dann gilt natürlich auch
und somit und
. Eve wählt also das erste Paar:
.
Ich behaupte, dass dieser Zug von Alice nicht optimal ist. Was, wenn
Sie statt den Index angefragt hätte?
Dann hätte sie das Tripel bekommen und Eve
hätte sich zwischen und entscheiden müssen.
Beide Paare sind für Alice besser kleiner als :
Wir folgern: optimalerweise zerlegt Alice immer das größere
der beiden Intervalle. Wir können nun alles zusammenfassen in folgender rekursiver Formel:
Nochmal in Worten und in einem Beispiel: in jedem Schritt ist es ziemlich offensichtlich,
welches der optimale Schritt für Eve ist; wir ersetzen
die Spielerin Eve also durch eine starre Regel und haben nun
ein Spiel mit nur einer Spielerin: Alice. Es ist also ein
Solitaire-Spiel, in welchem Alice in Zahlenpaar gegeben
hat und auf weitere, kleinere Paare "ziehen" kann, bis sie
das Paar erreicht hat. Ein Spielverlauf, startend
von , könnte also folgendmaßen aussehen:
und Alice braucht somit 5 Schritte. Geht es better? Versuchen wir es
noch einmal.
Auch wieder 5 Schritte.
Übungsaufgabe 1.3.2
Berechnen Sie per Hand für kleinere Werte von , zum Beispiel
für oder wie weit Sie halt kommen. Verwenden Sie die obige
rekursive Formel.
Übungsaufgabe 1.3.3
Schreiben Sie ein Elm-Programm (oder Java-Programm), das rekursiv berechnet.
Überprüfen Sie, ob in der Tat gilt, oder ob es eine
Zugreihenfolge gibt, die besser ist als die, die wir oben gefunden haben.
Hinweis. Mit List.range 1 (a-1)
erzeugen Sie die Liste [1, 2, ..., a-1].
Mit List.map können Sie dann den Ausdruck
für jedes in der Liste berechnen.
List.minimum berechnet Ihnen das Minimum einer Liste, gibt allerdings
ein Maybe Int zurück (das ist Elm-spezifisch, weil ja die leere Liste kein
Minimum hat); in unserem Fall wissen Sie mit Sicherheit, dass die Liste nicht leer ist,
dürfen
also irgendwas wie Maybe.withDefault verwenden:
Lesen Sie erst weiter, wenn Sie die beiden obigen Übungen gemacht haben oder sich ganz
sicher sind,
dass Sie die nicht machen wollen.
Analyse, Fortsetzung.
Da die rekursive Formel doch eher
kompliziert wirkt und uns nicht direkt eine Lösung einfällt, rechnen wir einfach mal
für kleine Werte aus.
Das heißt, wir legen eine Tabelle an, beschriften die Achsen mit und und schreiben
die Werte von
rein:
Die Werte
Gleiche Werte eingefärbt
Die Ecken der Farbklassen.
Die Ecken einer Farbklasse kommen in Paaren, z.B. und für die
Farbklasse 4. Das ist nicht überraschend, haben wir doch bereits früh die Symmetrie
bemerkt. Die Menge
also die Menge aller eingefärbten Zellen, schaut aus wie zwei übereinandergelegte Rechtecke,
nämlich der Dimensionen und . Und in der Tat:
Sehen wir uns diese Dimensionen, bzw. die Koordinaten der Eckpunkte genauer an:
Vielleicht "klingelt" es jetzt bei Ihnen. Dies sind die berühmten Fibonacci-Zahlen
mit dem rekursiven Bildungsgestzt
Jetzt sind wir bereit für den vorletzten Schritt bei der Suche nach einem Beweis.
Formulieren Sie eine Vermutung.
In unserem Falle heißt die Vermutung: die "Ecken" unserer Wertebereiche haben
die Koordinaten bzw. . Um das
mathematisch ganz präzise auszudrücken, müssen wir noch den Zusammenhang
zwischen und dem "Wert" herausfinden.
Zum Beispiel hat die eine Ecke von die Koordinaten
. Wir sind nun bereit, eine Vermutung zu formulieren.
Theorem. 1.3.5
Sei . Dann gilt genau dann, wenn
und ist.
Nun kommt der letzte Schritt bei der Suche nach einem Beweis: der Beweis selbst.
Beweis.
Wir einem "genau dann, wenn"-Satz müssen wir immer beide Richtungen beweisen.
Meistens ist eine davon einfacher. Wir beginnen mit:
Behauptung 1.
Wenn und , dann
ist . In anderen Worten, Alice hat eine Strategie, mit höchstens
Abfragen
das Maximum zu finden.
Dies ist die "einfache" Richtung, weil wir hier konkret eine
Strategie für Alice angeben können.
Beweis der Behauptung 1.
Wir verwenden Induktion über .
Induktionsbasis.Wenn ist, so
garantiert die Voraussetzung, dass .
Da und , so gilt nun .
In diesem Falle wissen wir bereits, dass gilt. Alice hat das Maximum
bereits gefunden: es liegt bei .
Induktionsschritt. Sei nun .
Alice kann das linke Intervall beliebig zerlegen, sagen wir
in
zwei Intervalle der Längen und . Wir erhalten drei Intervalle
der Längen
. Da , ist das erste Paar mindestens so groß
wie das zweite;
Eve wählt laso . Für die zweite Koordinate gilt
und somit, wegen Monotonie:
Nun wenden wir die Induktionshypothese für statt an und schlussfolgern,
dass
gilt. Alice kann das Maximum nun also mit weiteren
Zugriffen finden; sie tätigt also insgesamt Zugriffe.
Behauptung 2.
Wenn gilt und , dann
ist und .
Dies ist die "schwierigere" Richtung, weil wir hier alle möglichen
Züge von Alice berücksichtigen müssen.
Beweis der Behauptung 2.
Wir verwenden wiederum Induktion über .
Induktionsbasis.Wenn ist, so
ist nach Voraussetzung. Dies gilt
ausschließlich für und somit
gilt auch .
Induktionsschritt. Sei nun . Die Herausforderung ist,
dass wir nicht wissen, wie Alice das linke Interval zerlegt (wie oben argumentiert,
können wir
davon ausgehen, dass eine optimal spielende Alice immer das größere Intervall zerlegt).
Alice zerlegt das linke Intervall also in zwei Intervalle der Größe und
und erhält das Tripel .
Eve wählt nun das schlechtere der Paare und , also
jenes, für das größer wird. Nach Annehme verwendet Alice insgesamt höchstens
Zugriffe; nach dem Zugriff auf also noch weitere. Dies heißt
nun
Wenn ein Maximum höchstens ist, dann müssen beide Termine höchstens
sein.
Insbesondere
Wir wollen nun die Induktionshypothese auf anwenden. Ein Problem ist,
dass wir nicht wissen, ob oder größer ist. Dennoch: nach
Induktionshypothese ist
das größere höchstens und das kleinere höchstens , also
Wenn wir die beiden Ungleichungen addieren, erhalten wir
Auf der linken Seite addieren wir das Minimum und das Maximum, also einfach beide Werte,
und erhalten
. Also folgern , den ersten Teil unserer Behauptung.
Wir ziehen wir nun das zweite Argument aus raus und
erhalten
Wir wenden wiederum einen Induktionsschritt an und erhalten
, woraus sofort
folgt.
Wir haben nun und , wie verlangt.
Mit Behauptung 1 und Behauptung 2 haben wir beide Richtungen des "genau dann, wenn"-Satzes
gezeigt
und beschließen somit den Beweis des Theorems.
Ein Schlussstein fehlt noch. In dem obigen Theorem betrachten wir das Szenario, dass Alice
mit den drei "stark roten" Array-Positionen arbeitet.
Wie soll Alice allerdings am Anfang verfahren, wenn sie von dem Array noch
keinen
einzigen Index angefragt hat?
Bezeichnen wir mit den ersten Index, den Alice anfragt. Alice kennt nun also
drei Werte: und per Konvention und
durch den ersten Zugriff, den sie getätigt hat. Alice verfügt nun also über
zwei Intervalle der Längen und und benötigt daher bei optimalem Spiel
Schritte.
Wie soll Alice nun den ersten Index wählen? Wenn selbst eine Fibonacci-Zahl
ist, dann könnte sie wählen und danach
weitere Zugriffe tätigen; wir haben hier das obige Theorem verwendet. Zusammen mit dem ersten
Zugriff, den auf , tätigt Alice genau viele. Daher ergibt sich folgende Vermutung
/ folgendes Theorem.
Theorem 1.3.6
Sei ein unimodales Array aus Zahlen und
sei die kleinste natürliche Zahl, für die gilt. Dann
kann Alice das Maximum von mit Zugriffen finden, und dies ist im Worst-Case auch
optimal.
Beweis.
Dass Alice es kann, haben wir schon (fast) gesehen. Alice fragt an und
erhält somit zwei Intervalle der Längen und und kann
nun das vorherige Theorem anwenden und insgesamt Anfragen tätigen.
Um zu zeigen, dass Alice im Worst-Case auch tatsälich Anfragen benötigt,
drehen wir die Dinge um: wir nehmen an, dass es Alice mit Anfragen schafft und
zeigen, dass gelten muss.
Sei nun
der erste Index, den Alice anfragt. Damit erhält sie zwei Intevalle
der Längen und . Da wir nicht wissen, ob oder größer ist,
führen wir zwei neue Bezeichner ein:
und . Jetzt gilt auf jeden Fall
und . Da Alice weitere Zugriffe macht,
also , gilt nach Theorem
und somit
, wie behauptet.
Quantitative Analyse
Was heißt das nun quantitativ? Wie verhält sich die optimale Anzahl von Anfragen in Abhängigkeit von
?
Hierfür müssen wir untersuchen, wie groß ist. Beachten Sie, dass " ist groß"
gut für Alice ist: sie kann dann auch große unimodale Arrays mit höchstens Zugriffen
maximieren.
Ganz Allgemein ist es in der Mathematik unglaublich hilfreich, gewisse Größen "emotional" zu
besetzen, also
zum Beispiel "großes F_{k} ist gut" oder "großes ist schlecht" oder "große
Intervall-Längen sind schlecht".
Wenn Sie "emotional" wissen, was gut ist und was schlecht, dann werden Sie Ungleichungszeichen wie
und nicht verwechseln.
Wir müssen also die Größe von abschätzen, im Prinzip eine Formel für entwickeln.
Auch hier
werde ich wieder extrem detailliert vorgehen und Sie auch an der Beweisfindung
teilhaben lassen.
Als erstes will ich eine obere Schranke für finden, also argumentieren, dass die
Fibonacci-Zahlen
nicht allzu schnell wachsen. Als eine erste Beobachtung haben wir
weil (warum?). Das heißt also, die Fibonacci-Zahlen wachsen in jedem
Schritt um
höchstens das doppelte.
Lemma. 1.3.7.
Übungsaufgabe 1.3.4
Beweisen Sie das Lemma. Führen Sie möglichst rigoros und detailliert einen induktiven Beweis
durch.
"Lemma". 1.3.8.
Übungsaufgabe 1.3.5
(1) "Beweisen" Sie das Lemma mithilfe von Induktion; (2) scheitern Sie, denn das Lemma ist so
nicht korrekt; (3) korrigieren Sie das Lemma in sinnvoller Weise; (4) beweisen Sie rigoros
die korrigierte Version.
Übungsaufgabe 1.3.6
Verallgemeinern Sie. Statt und : Was ist die kleinste
Zahl , für die Sie beweisen können?
Was ist die größte Zahl , für die Sie
oder zumindest beweisen können?
Spoiler alert. Lesen Sie erst weiter, wenn Sie die
letzten drei Übungsaufgaben gelöst haben oder zumindest signifikant
Zeit in sie investiert haben.
Manchmal kann es nütztlich sein, mathematische Strenge
ein wenig fallen zu lassen und Dinge zu beweisen,
die zwar falsch aber eben fast wahr sind. Wir haben weiter
oben zum Beispiel Theoreme der Form
bzw. bewiesen.
Können wir beweisen? Sicherlich nicht, denn die Behauptung
ist schlicht falsch. Denn angenommen, sie würde gelten,
dann hätten wir auch
das heißt, aufeinanderfolgende Fibonacci-Zahlen müssten
immer das gleiche Verhältnis aufweisen, was mit
Beispielen wie einfach zu widerlegen ist.
Dennoch: tun wir mal so, als wüssten wir das alles nicht und versuchen,
ein entsprechendes Theorem einfach mal zu beweisen.
"Theorem" (falsch) 1.3.9
Es gibt ein , sodass für alle
gilt.
Beweis.
Wir beweisen das Theorem durch Induktion über . Sei
. Dann gilt
Die Gleichung stimmt genau dann, wenn
also .
Dies ist eine quadratische Gleichung und besitzt zwei Lösungen:
Welches ist nun das "richtige"? Schauen wir in unser "Theorem":
wir suchen ein , also ist das "richtige",
also .
Das Theorem ist natürlich falsch. Aber wo im Beweis haben wir einen Fehler
gemacht?
Übungsaufgabe 1.3.7
Finden Sie den Fehler im Beweis.
Ganz klar: wir haben die Induktionsbasis vergessen. Wir hätten zeigen
müssen, dass und gelten, und dies haben wir
versäumt. Aber immerhin: die Zahlenfolge
mit
besitzt, genau wie die Fibonacci-Folge, die Eigenschaft, dass
.
Definition. 1.3.10
Eine Zahlenfolge heißt
Fibonacci-artig, wenn
für alle gilt.
Beispiele für Fibonacci-artige Zahlenfolgen:
für wie oben;
für wie oben;
, die Fibonacci-Zahlen selbst;
Dies sind natürlich nicht alle. Wir können
Folgen gliedweise addieren. Definieren wir zum Beispiel eine
Folge mittels . Dann gilt
Voilà, wir bekommen eine neue Fibonacci-artige Folge. Wir können die beiden
Anteile und auch unterschiedlich gewichten:
Übungsaufgabe 1.3.8
Für zwei reelle Zahlen definieren wir
.
Zeigen Sie, dass die Folge auch
Fibonacci-artig ist.
Was bringt uns dies? Nun ja, wir können jetzt mit den Werten
für und rumspielen und schauen, wie sich
die Werte verändern:
Können wir nun so wählen, dass und gilt?
Wenn ja, dann würde unsere Folge die folgenden drei Kriterien erfüllen:
und somit wäre sie identisch zu den
Fibonacci-Zahlen: ; wir hätten eine explizite Formel für alle Fibonacci-Zahlen
gefunden. Also: wir wollen Zahlen mit
Dies ist ein System mit zwei Gleichungen und zwei unbekannten und sollte
somit genau eine Lösung haben (außer wenn die beiden Gleichungen linear abhängig
sind, was sie aber nicht sind).
Übungsaufgabe 1.3.9
Lösen Sie das obige Gleichungssystem (erinnern Sie sich, dass
und per
Definition).
Wir haben nun also
Theorem. 1.3.11 .
Beachten Sie, dass der zweiten Summand der Formel
mit steigenden immer kleiner wird (im Absolutbetrag), und somit
und somit ist der erste Summand
höchstens von der ganzen Zahl entfernt.
Daher gilt auch .
Anzahl Zugriffe für Maximierung unimodaler Arrays
Blicken wir zurück auf Theorem 1.13: wenn ist,
dann reichen Zugriffe, um in einem unimodalen Array der Länge das
Maximum zu finden. Wenn
gilt, dann sicherlich auch,
da die rechte Seite ja höchstens ist. Wir formen
nun diese Bedingung weiter um:
Zusammenfassend: wir finden das Maximum mit ungefähr
Zugriffen (plus minus);
mit naiver Binärsuche, die in einem Halbierungsschritt
und anfragt, kommen wir auf ungefähr
, was deutlich schlechter ist.
Abschließende Bemerkungen.
Mit dem zurückliegenden Kapitel wollte ich zwei Ziele erreichen.
Zweitens wollte ich Ihnen anhand des Problems, das
Maximum in einem unimodalen Arrays zu finden, illustrieren,
wie man durch Abstrahieren, Vereinfachen, Herumprobieren etc. sich langsam
vorarbeitet, bis man schlussendlich eine Vermutung formulieren und dann
beweisen kann; es war also ein "Crash-Kurs in mathematischer Praxis",
wobei "Praxis" nicht heißt, dass es ein im praktischen Leben relevantes
Problem wäre, sondern dass es die Praxis mathematischer Arbeit illustriert hat.
Erstens schließlich haben wir in diesem Kapitel das Prinzip der
binären Suche kennengelernt, welches Ihnen (unter
den richtigen Umständen) erlaubt, Ihr gesuchtes Objekt
in (ungefähr) Schritten zu finden, statt
in Schritten, wenn Sie Ihre gesamte Datenmenge durchgehen müssen.
Im Allgemeinen funktioniert binäre Suche, wenn Ihre Daten sinnvoll sortiert
sind (zum Beispiel alphabetisch in unseren ersten Beispielen).
Im nächsten Kapitel beschäftigen wir uns damit, wie man eine Datenmenge
(also im Allgemeinen ein Array) sortiert.