3.3 Binäre Suchbäume
In vielen Fällen wollen wir nicht nur am Anfang oder Ende unserer Datenstruktur etwas schreiben, sondern an beliebigen Stellen. Ganz allgemein wünschen wir uns eine Datenstruktur, die folgende Operationen unterstützt:
find <key> // findet das Paar (key,value) und gibt value zurück (oder null, wenn nicht vorhanden) insert <key> <value> // fügt das Paar (key,value) ein und löscht ein etwaiges älteres Paar (key, oldValue) delete <key> // löscht das Paar (key,value), sofern vorhanden
Wir wollen also Key-Value-Paare speichern, ähnlich wie in der Liste german-words.txt. Eine solche Datenstruktur nennt man im Allgemeinen ein Dictionary. Die meisten Programmiersprachen bieten Dictionarys bereits in der ein oder anderen Form an. Hier setzen wir uns mit den Möglichkeiten auseinander, ein solches zu implementieren und untersuchen jeweils, wie schnell (oder langsam) die jeweiligen Operationen sind.
- Als Stack, also z.B. verkettete Liste.
find <key>: wir müssen, wenn wir Pech haben, die ganze Liste durchlaufen;insert <key> <value>: wir legen das Paar einfach auf den Stack drauf; das brauchtdelete <key>: gleich wiefind
- Als Array, das immer nach den Werten der Schlüssel sortiert ist
(z.B. alphabetisch, aufsteigend).
find <key>: Wir wenden binäre Suche an:insert <key> <value>: Wir können den Einfügeort mittels binärer Suche schnell finden, müssen dann aber alles, was danach kommt, um eins nach rechts verschieben:delete <key>: gleiches wiefind; wir können zwar mittels binärer Suche die Stelle finden, müssen aber alles, was rechts davon steht, um eins nach links verschieben.
Um alle drei Operationen insert, find, delete in schneller
(hier:
- ein leerer Baum ist, bestehend aus einem Blatt, oder
- ein innerer Knoten mit einem Datenelement (beispielsweies einem String) und einem linken Kind und einem rechten Kind, die wiederum Binärbäume sind.

Den obersten Knoten nennen wir die Wurzel. Es ist recht problemlos, Binärbäume als Datentypen in Java oder Elm zu definieren.
public class BST {public String data;public BST leftChild;public BST rightChild;public BST (String data, BST left, BST right) {this.data = data;leftChild = left;rightChild = right;}}
module BST exposing (..)type BST= Leaf| Node String BST BST
Den folgenden Baum:

können wir dann wie folgt erzeugen:
// in Java
BST tree = new BST("z", new BST("e", null, new BST ("a", null, null)), null);
-- in Elm
tree: BST
tree = Node "z" (Node "e" Leaf (Node "a" Leaf Leaf)) Leaf
Binäre Suchbäume (Binary Search Trees, BST)
Ein Binärbaum ist ein Binärer Suchbaum (Abkürzung BST), wenn die in den inneren Knoten gespeicherten Elemente geordnet sind; konkret: wenn ein innerer Knoten das Element



















insert, find, delete experimentieren.
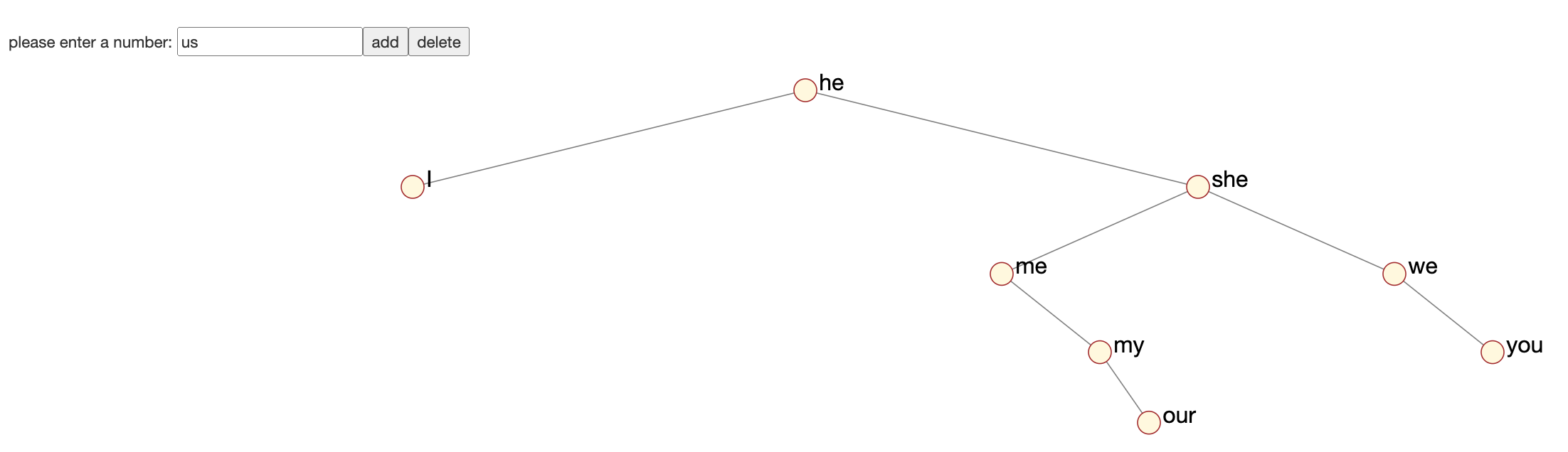
Im folgenden werden wir BSTs formal definieren und Methoden zum Suchen, Einfügen und Löschen finden.
Ein binärer Suchbaum, kurz BST (vom Englischen binary search
tree)
ist wie folgt rekursiv definiert: es ist entweder ein leerer Baum,
den wir mit
- wir
- alle Keys in
- alle Keys in
Beachten Sie, dass wir im obigen Beispiel mit of, to, in...
die leeren BSTs nicht gezeichnet haben. Mit den leeren BSTs müsste das Endergebnis
des oberen Baums dann so aussehen:
Der (Pseudo-) Code für Suchen (find) und Einfügen (insert)
in einem BST
schreibt sich fast von selbst:

Der Code für das Einfügen ist nur leicht komplizierter:

Löschen ist etwas schwieriger. Ich teile es auf in
delete, was erst einmal den Key überhaupt
sucht und dann deleteRoot aufruft, was den Wurzelknoten mitsamt
Key löscht.

Für delRoot müssen wir uns was überlegen. Einfach ist es,
wenn der linke Teilbaum leer ist; dann ergibt delRoot(T) einfach
den rechten Teilbaum. Ganz analog, wenn der rechte Teilbaum leer ist:
Wenn aber weder der linke noch der rechte Teilbaum leer ist, was dann?
Eine Idee wäre, im rechten Teilbaum

Ich hatte fehlerhaft angenommen, dass das Minimum von
findMin
und deleteMin.
he, by, or, on, do, if, me ein.
of.
Ganz allgemein finden wir BSTs gut, wenn Sie geringe Höhe haben.
Die Höhe eines Baumes ist der Abstand von der Wurzel zu dem am weitesten
entfernten Blatt. Wir schreiben

und damit
Finden Sie ein Array
Tip. Meine Beispiel-Arrays haben Größe 4 bzw. 5. Ich habe also ein Array der Länge 5, welches mir einen Baum der Höhe 2 gibt; wenn allerdings das erste Element im Array nicht da wäre, würde das restliche Array (der Länge 4) mir einen Baum der Höhe 3 (also schlechter) geben.
array gefunden, für das gilt
find, insert, delete in einen
BST ist begrenzt durch die Höhe des Baumes, also
die Länge des längsten Pfades von der Wurzel zu einem Blatt.
insert-Operationen,
die insgesamt quadratisch viele Schritte verursacht, also
Die Herausforderung ist nun, die Implementierung von Binärbäumen so anzupassen,
dass keine degenerierten Bäume entstehen, dass also idealerweise
die Höhe des Baumes möglichst klein ist. Wie klein kann sie überhaupt sein?
Wenn ein Baum Höhe
Soweit die untere Schranke.
Dieses Optimum von insert und delete deutlich komplexer
als für "naive" BSTs.
- Treaps. Wir haben bereits gesehen,
dass BSTs besonders schlecht werden, wenn die Elemente in geordneter
Reihenfolge eingefügt werden. Was, wenn die Reihenfolge zufällig ist?
Treaps simulieren eine zufällige Einfüge-Reihenfolge, indem sie jedem
Schlüssel-Wert-Paar ein Gewicht zuordnen. "Leichte" Elemente
sollen dann im BST höher stehen als "schwere".
Dies garantiert, dass der BST immer so aussieht, als hätten wir die Elemente
von leicht nach schwer sortiert eingefügt. Wenn wir schließlich die
Gewichte zufällig wählen, sieht der BST so aus, als
hätten wir die Elemente in zufälliger Reihenfolge eingefügt.
Vorteil. Treaps sind recht einfach zu implementieren; wir müssen nur pro Element zusätzlich ein Gewicht speichern.
Nachteil. Treaps sind randomisiert; alle oberen Schranken gelten also nur im Erwartungswert. Das heißt, Sie können rein theoretisch Pech haben und mit einem degenerierten Baum und hohen Suchzeiten enden. Die Laufzeitanalyse ist moderat kompliziert (wenn Sie keine Erfahrung mit Wahrscheinlichkeitsrechnung haben).
- B-Bäume. Der Idealfall eines BSTs ist ja,
dass er perfekt balanciert ist, also alle Blätter gleichen Abstand
von der Wurzel haben. Das geht aber selbst theoretisch nur dann,
wenn die Anzahl der Elemente die Form
Vorteil. Die Laufzeitanalyse ist extrem einfach. Die Höhe ist immer maximal
Nachteil. Die Implementierung ist etwas komplizierter.
- Rot-Schwarz-Bäume (Red-Black-Trees).
Dies sind wiederum "richtige" BSTs, in denen jeder innere Knoten
genau zwei Kinder hat. Jeder innere Knoten bekommt eine
Farbe Schwarz oder Rot, die gewissen Regeln unterworfen sind.
Diese Regeln helfen uns, sicherzustellen, dass die Höhe
des Baumes immer
Vorteil. Rot-Schwarz-Bäume sind BSTs, und dadurch ist der Code für
findgenau der Gleiche wie für naive BSTs. Die Laufzeitanalyse ist offensichtlich.Nachteil. Die Regeln für
insertunddeletemüssen mehrere verschiedene Fälle von Knotenfärbungen beachten; das erschwert die Implementierung und auch das Verständnis.
Beachten Sie, dass in der Praxis weitere Vor- und Nachteile dazukommen können, die von Anwendungsfall zu Anwedungsfall variieren. Schwierigkeit der Laufzeitanalyse und Schwierigkeit der Implementierung sind für die Praxis auch nicht wirklich von Relevanz, da Sie ja meistens auf Implementierungen zurückgreifen können.