SoKonBe: Externe, pädagogisch-psychologische Beratung von Dozenten/innen zur Verbesserung der Lehrqualität mit Fokus auf effektiver Nutzung sozio-kognitiver Konflikte |

|
Datenmanagement
Einblick in das Verwalten von Massendaten
Der häufig in der sozialwissenschaftlichen Forschung benutzte Weg besteht aus der Generierung, der Speicherung und Analyse der Forschungsdaten in einer Programmanwendung. Typisch sind Excel und SPSS. Ebenso werden Daten in generischen (allen Anwendungen offen stehenden) Formaten gespeichert, die dann mit spezifischen Programmskripten analysiert werden. Typisch sind hier beispielsweise binäre oder textorientierte Speicherformate.

Dieser Ablauf eignet sich immer, wenn nur geringe Mengen, wenig verzweigte Messdaten analysiert und behandelt werden müssen. Auch wenn nur eine Person an den Daten arbeitet, kann dieses System erfolgreich angewendet werden.
Problematisch wird dieses System immer dann, wenn:
- viele Person gleichzeitig an Datensätzen arbeiten (Upload und Bearbeiten)
- Daten weitverzweigte Abhängigkeiten besitzen (hier z.B.: Die Daten eines Dozenten sind mit mehreren Studenten verknüpft, deren Daten wiederum mit verschiedenen Dozenten verknüpft sind.)
- komplexe Fragestellungen, komplexe Abfrage- und Analysemethoden erfordern
- EXCEL und SPSS mit der Speicherung und Anzeige der Daten überfordert sind (Typischerweise ab ca. 500.000 Datensätzen)
Aber Achtung: Auch wenn einzelne Dateien selbst wenige Datensätze beinhalten, können sich die einzelnen Datendimensionen zu beachtlicher Größe multiplizieren. Ein bekanntes Problem ist dabei das „Schachbrett x Reiskorn – Problem“ (http://www-math.upb.de/~mathkit/Inhalte/Folgen/data/manifest25/schachbrett_reiskoerner.html)
In unserem Projekt verteilt sich die Datenmenge wie folgt:

Dies erforderte eine Änderung des klassischen Analyseweges unter Zuhilfenahme eines Datenbankmanagementsystems (DBMS).
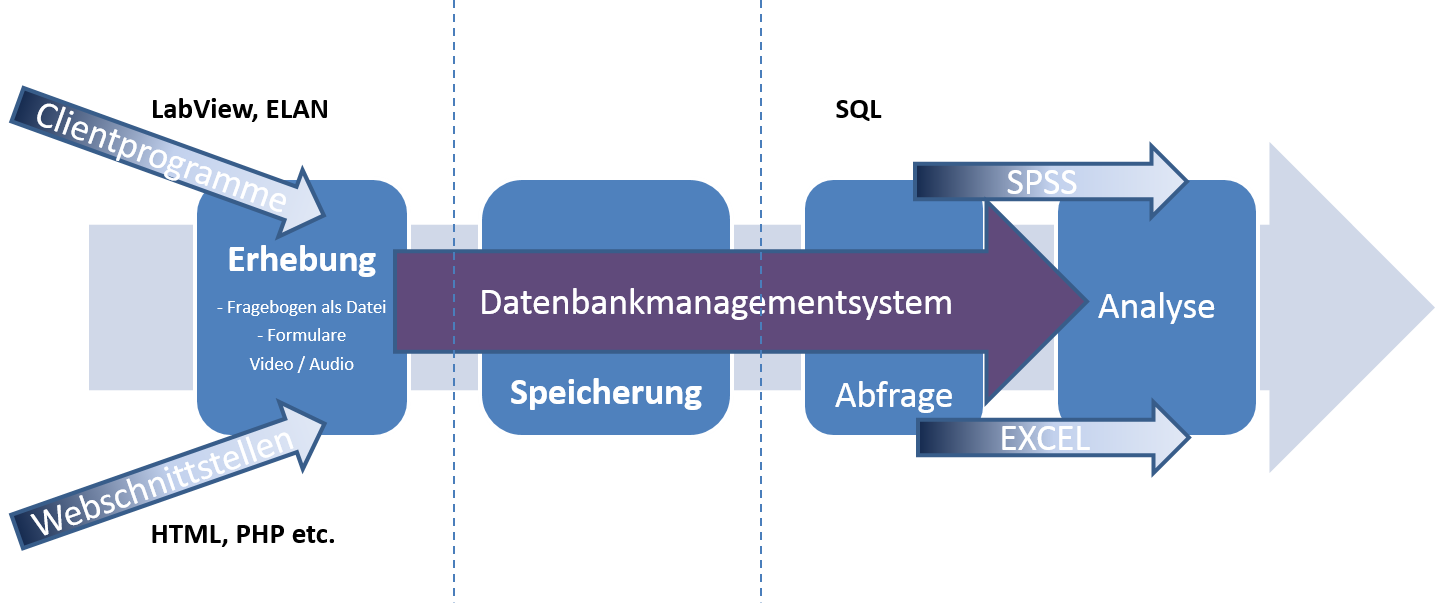
Daten werden aus verschiedenen Quellen (Onlinebefragungen, Video(-rating)portal, Paper-& Pencil-Umfragen, Videoannotationssoftware ELAN etc.) generiert. Wir versuchen alle Daten möglichst vom Teilnehmer direkt als computerverarbeitbare Daten zu erhalten, um Übertragungsfehler zu vermeiden und zeiteffizient arbeiten zu können. Wo dies durchführungsbedingt nicht möglich ist (v.a. Studentenbefragungen während der Videoaufnahme), haben wir den Mitarbeitern, welche die Daten eingeben, ein Clientformular zur Seite gestellt, welches exakt das Papierformular abbildet.
Der Upload der Daten kann für die Teilnehmer und Mitarbeiter bequem am Arbeitsplatz vor Ort, aber auch am heimischen PC erfolgen. Ein gleichzeitiger Zugriff ist ohne Probleme möglich. Die Daten werden außerdem auf grobe Plausibilitätsfehler geprüft.
Diese Fehler liegen nachweisbar bei unter 0,03%.
Die Daten werden in der zentralen Datenbank abgelegt und regelmäßig gesichert. Derzeit können wir theoretisch jede Version bis zum Beginn des Projektes wiederherstellen. Wir verwenden das OpenSource DBMS „PostgreeSQL“.
Die Daten können wiederum gleichzeitig von verschiedenen Mitarbeitern abgerufen werden. Hierbei ist die implementierte Rechtevergabe von besonderem Vorteil. Somit haben bestimmte Mitarbeiter beispielsweise nur Zugriff auf vollständig anonymisierte Daten, während eine andere Gruppe, die sich beispielsweise mit der Akquise neuer Teilnehmer beschäftigt, Klarnamen und Adressen einsehen kann.
Im Anschluss können die Daten durch SQL-Befehle aggregiert (zusammengefasst, ausgewählt und gruppiert) und einer tieferen Analyse zugeführt werden. Ziel beim Aggregieren von Daten ist die Mengenreduktion durch Vorauswahl und Durchführung einfacher Vorberechnungen (Mittelwerte, Prozentuale Anteile etc.). Hier ist die zentrale Struktur von DBMS von Vorteil. Vor allem in dieser frühen Phase der Auswertung wären Arbeitsplatzrechner häufig mit den zwar wenig komplexen, dafür aber hohen Anzahl von Operationen überfordert.

Abfragen werden bei DBMS aber serverseitig bearbeitet. Somit muss lediglich der Datenbankserver „schnell“ sein. Der abfragende Clientrechner benötigt hingegen keine besondere Performanz. Den speziellen Anforderungen innerhalb unseres Projektes wird serverseitig aber schon ein gängiger, mit Solid-State-Drive Festplatten (SSD) ausgerüsteter Rechner, gerecht. Da innerhalb des Projektes kaum Parallelanfragen mehrerer Clients verarbeitet werden müssen, achten wir weniger auf Prozessorperformanz als auf schnelle Schreib–Lese–Zugriffsraten, welche aber von gängigen SSD´s erreicht werden. Somit ist die Einrichtung eines DBMS eine kostengünstige Sache.
Die Gesamtstruktur gliedert sich folgendermaßen:
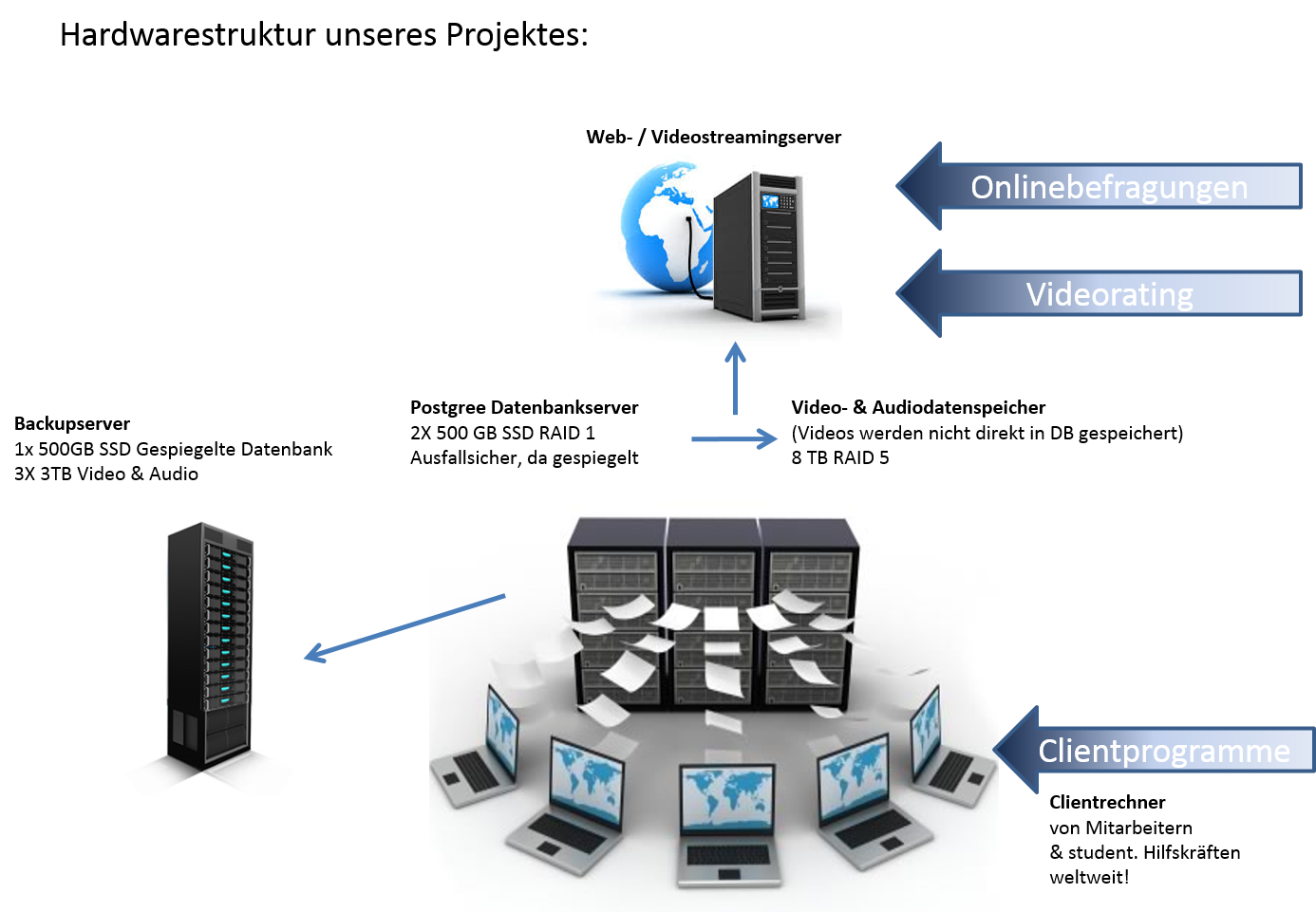
Bildquellen: hackerrank.com, shark-systems.de, pccentre.com
{kind=link}
{kind=link}
Kontakt bei Rückfragen: Conrad Koczielski, Daniel Trommler