
TransGrimm
The interdisciplinary TransGrimm project applies linguistic, literary and computational approaches to the comparative study of the Grimms' fairy tales and their translations.
TransGrimm Corpus and web-based interface
The corpus
#/media/File:Household_stories_Bros_Grimm_(L_&_W_Crane)_title_page.png)
The TransGrimm corpus, which is currently being compiled by the TransGrimm group at the TU Chemnitz, is an aligned multi-parallel corpus of all the published German versions of the world-renowned Kinder- und Hausmärchen (KHM) collected by the brothers Jacob and Wilhelm Grimm, as well as their English translations, although plans exist to expand the corpus to also include translations into other languages. The TransGrimm corpus is an aligned corpus, meaning that each fairy tale and its respective translations are divided into segments or ‘chunks’ of a certain length (which may correspond to a clause, a sentence or a paragraph), with equivalent chunks cross-linked (‘aligned’) using various methods (such as a tabular format or indexation). This allows one to compare the changes (such as additions/omissions) introduced into the fairy tale either by the original authors over time or by the individual translators. For an example of the multi-parallel alignment that is the hallmark of the TransGrimm corpus, see the Rapunzel excerpt below. Early stages of the corpus compilation process consisted of manual alignment by a student assistant. Presently, however, the project group is developing a neural networks-based automated alignment algorithm called NeurAligner.
„Rapunzel, Rapunzel, laß mir dein Haar herunter."
„Rapunzel, Rapunzel, laß dein Haar herunter."
"Lettice, Lettice, let down your hair, That I may climb without a stair."
"Rapunzel, Rapunzel, Let down thy hair to me."
Alignment example featuring an excerpt from the "Rapunzel" (KHM 012, alignment chunk 34) fairy tale
The web-based corpus interface
To make our TransGrimm corpus available to the public in an easily searchable format, we are currently developing a web-based interface for it, which will be freely accessible once completed. The webtool will adapt the traditional KWIC (keyword-in-context) view, familiar to everyone from non-aligned corpora, to the display of aligned multi-parallel corpus query results. The hits will be presented as a list of KWIC items in the middle of the page, flanked by their immediate context on either side. However, unlike in the aligned corpus webtools available to date, the hits will be displayed vertically (from top to bottom) instead of horizontally (from left to right), permitting a fast and clear overview of the differences and similarities between parallel segments. We also plan to integrate a machine translation module into the corpus query process in order to translate the query term into the other available language, so that its equivalent can also be highlighted and centrally aligned on the page. The below screenshot of the TransGrimm webtool mockup demonstrates this idea usind the example of the query term great*.
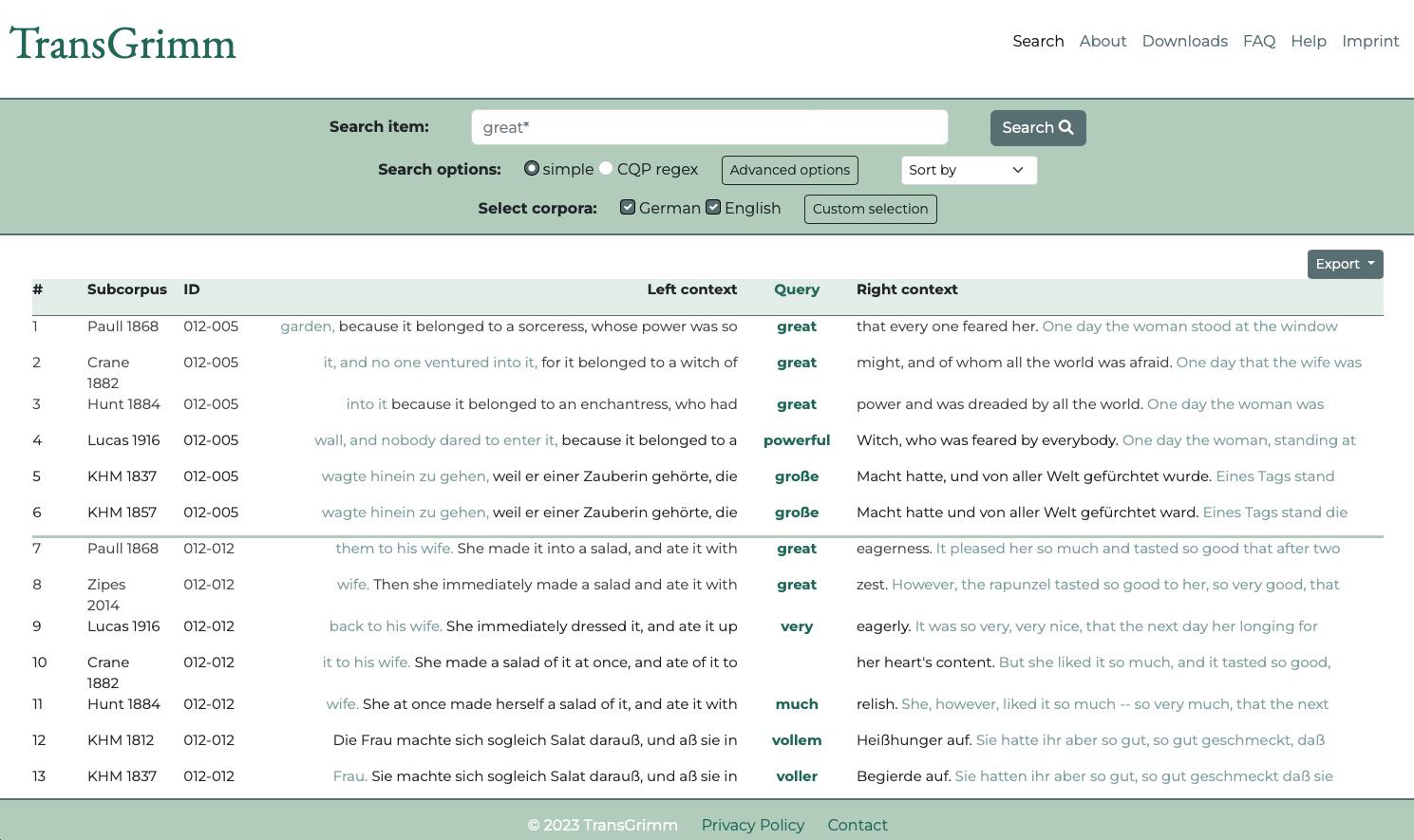
Mockup of the upcoming TransGrimm corpus webtool (screenshot; click to enlarge)
Current projects
First and Last Lines
If asked how fairy tales tend to begin, most people would probably answer that they start with the formula es war(en) einmal in German and its equivalent once upon a time in English. To test this belief about fairy tale openings, as well as to discover the most common ways in which fairy tales tend to conclude, we devised the present quantitative corpus-based study of the first and last lines in the last version of the KHM from 1857 and in one of its English translations (Hunt 1884). In the study we analyzed a variety of features, such as the frequencies of various well-known opening and closing variants, n-grams, first-named entities, collocations of lebte(n)/lived and references to time. We also conducted a diachronic analysis of the phrases es war(en) einmal and once opon a time using Google Ngrams and the COCA corpus.
Publications
Sanchez-Stockhammer, C. 2020. The potential of multi-word units as measures of fairy-tale style in Schneewittchen (Snow-White) and its English translations. In L. Fesenmeier & I. Novakova (eds.), Phraséologie et stylistique de la langue littéraire, 305–327. Berlin.
Presentations
Sanchez-Stockhammer, C. & A. Yurchenko. 2023. Building blocks of fairy tale openings and closings in the TransGrimm Corpus. 12th International Corpus Linguistics Conference (CL2023), Lancaster, UK.
Sanchez-Stockhammer, C. & A. Yurchenko. 2022. "A contrastive corpus-based study of German and English fairy tale openings and closings". ICAME 43, Cambridge, UK.
Team
Project coordinator and PI: Prof. Dr. Christina Sanchez-Stockhammer
Corpus compilation, alignment, software development: Johannes Tochtermann, Mathis Jeromin, Steve Dionglay, Sasha Coelho, Asya Yurchenko